
北京某某塑料板材有限公司
诚信 / 务实 / 完善 / 快速 / 放心 - 国际品牌
咨询热线: 020-88888888
当前位置: 主页 > 资讯中心 > 行业动态 » 最优化方法复习笔记(一)梯度下降法、精确线搜索与非精确线搜索(推导+程序)

最优化方法期中考试考得并不理想=_=。
算了~~~多余的时间想给自己来一次非常不地道的哈尔莫斯教学法,算是对大二咸鱼生活的一点补充吧。
大概就是把最优化方法的知识点整理一遍,写一个十篇文章的系列。
如果你也是正在学习最优化方法的本科生或者研究生(或者高中生),欢迎多多交流。
梯度下降法又称为最速下降法,是最优化方法中最基本的一种方法。不过随着ML的热火,梯度下降这个名词估计也满街飞了。
所有的无约束最优化问题无非是在求解如下的无约束优化问题:
如果我们想要通过迭代的方式,将初始点
?逐步迭代到最优解所在的点
?,那么我们就会考虑这样的一个搜索点迭代过程:
其中
是我们根据目标函数在
的情况确定的搜索方向,而
则称为迭代点
沿搜索方向的步长。因此,我们需要寻求一种算法,在已知函数
和迭代点
的情况下,能够算出搜索方向
,使得
在这个搜索方向下得到的点能够使得
变小,即:
如果只是单纯地希望得到的新迭代点能够使得?的值变小,那么新的迭代点很好找,直接通过坐标下降法这种无梯度的方法就可以达到目的。然而梯度下降法希望得到一个在该点下降最快的方向,来使得我们的迭代过程尽可能的高效。
如何确定这个式子中的?将是我们所有含梯度下降法的思路出发点。
初等微积分的知识告诉我们,某一点处的梯度方向是函数值增长最快的方向,那么梯度的反方向就是函数值下降最快的方向。因此在函数一阶可微的情况下,我们直接求取 ?,那么?
就是函数下降方向最快的方向了。
需要说明的是,下降最快不代表下降幅度最大
下面我们证明这一点:
设目标函数 ?连续可微,将?
在?
处Taylor展开:
令?
,结合
迭代法?可得:
若我们的迭代过程是切实可行的、能够收敛的,那么很显然有?
。因此,我们有:
?。
为了使得本次迭代能够使得 ?,需要确保
?随着?
的增大而减小(
的小领域内),即?
,而且我们希望?
下降得尽可能快,也就是我们想要的?满足:
由Cauchy不等式:
根据Cauchy不等式成立的条件, ?需要与
?同向。所以我们想要寻找的下降最快的方向
?与
?同向。
因此,梯度下降法只考虑了当前的函数关于?下降最快的方向。
于是我们找到了一种可行的搜索方向。因此,梯度下降法也就容易得出了:(此处线搜索会在后面提到)
当然,假设目标函数在搜索空间上是连续的,则终止条件也可以写成?或者

上述梯度下降法的描述中,线搜索是什么还没有说。其实线搜索是一个和最优化方法捆绑销售的一个概念。你完全可以把线搜索放在梯度下降法中来理解。
我的理解是这样的:当梯度下降发进行到第二步时,更新迭代式 中我们只有
不知道其具体的值,所以我们必须得通过某种方法来确定
的值,而确定
的方法称为线搜索。为什么叫做线索搜呢?个人理解为
是正实数,而正实数在三维空间中张成的搜索空间是一条与坐标轴平行的射线。
我们确定 的方式有两种:精确线搜索和非精确线搜索。精确线搜索的目的是找到
在
上的最小值。
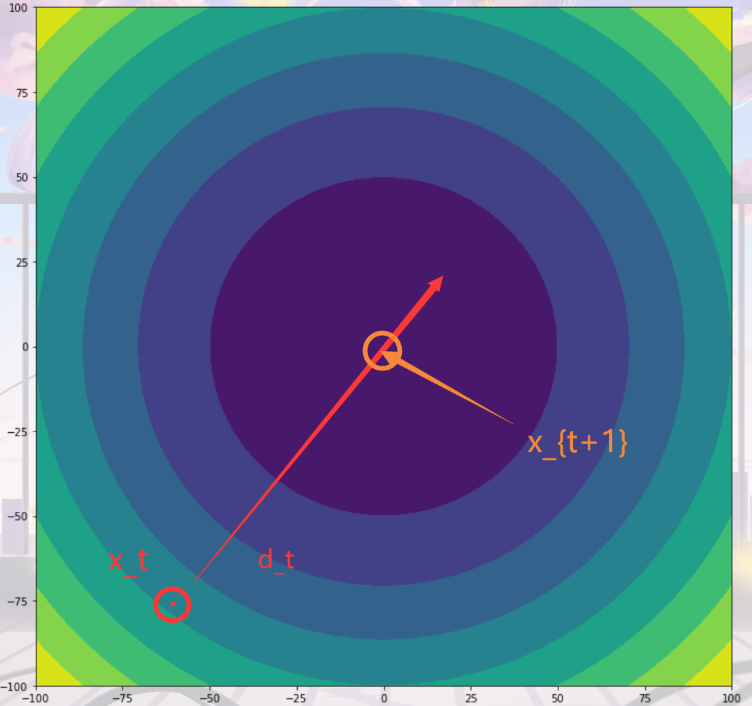
如上图,精确线搜得到是一个具体的值,这个值往往可以通过研究?在
?上的极值点来确定。
但是很多时候? 的极值点没有解析解,只有数值解,那么为了确定唯一的最小值点?,我们只能遍历?
的整个搜索空间,但这会极大提高梯度下降法的时间复杂度,此时精确线搜会让我们的优化算法变得极其低效(比如Python的
scipy的优化方法子库,默认使用0.618法进行精确线搜索)。这个时候,就需要使用非精确线搜来确定? 。不同于精确线搜索,非精确线搜不要求一定要在每一次迭代中找到那个使得
?最小的
?,而是通过某些非精确线搜准则来找到一个接近最佳搜索步长
?的步长
?,这个步长能够使得目标函数在该次迭代中下降和?
差不多的幅度。
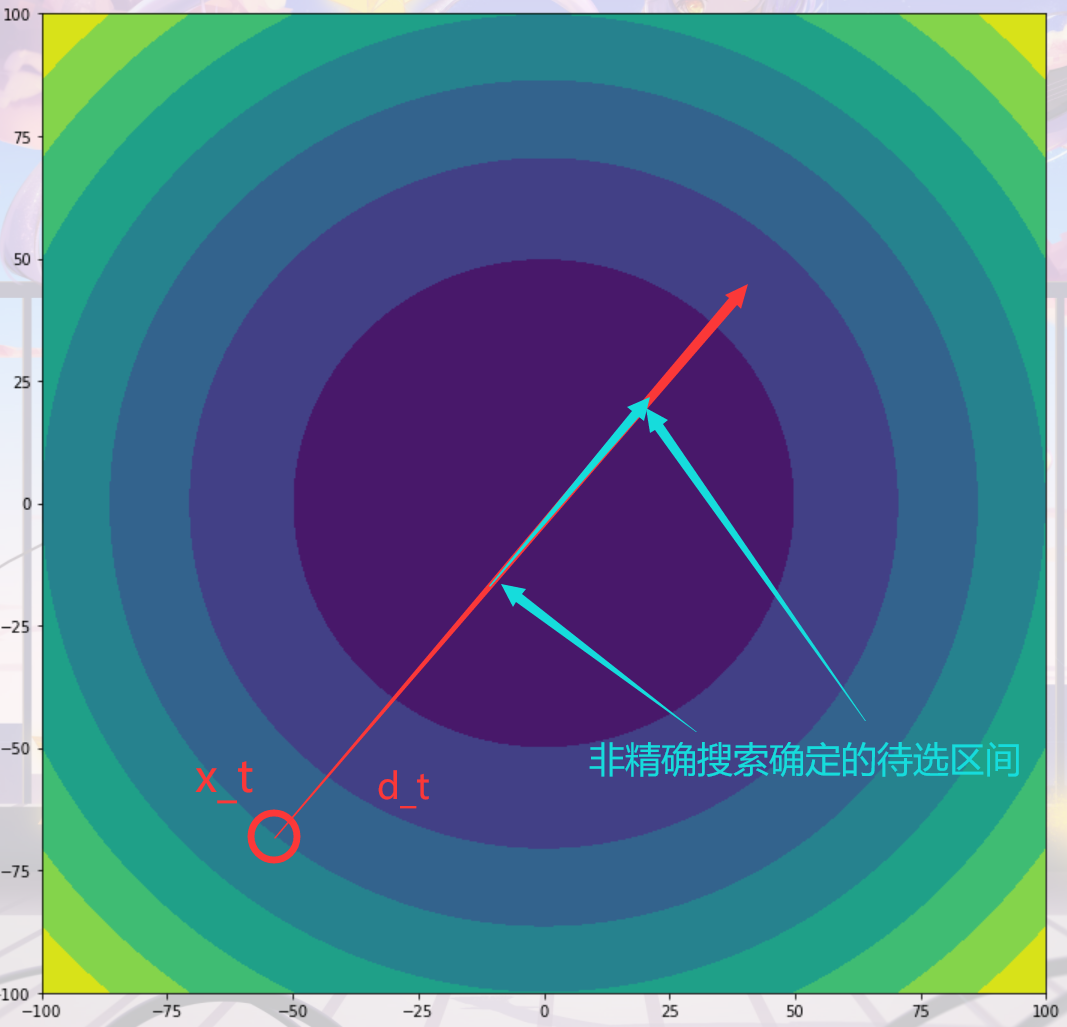
如上图,非精确线搜索确定了?的大致区间
其实除了以上两种,还有一种最朴素的方法:固定步长。也就是选取一个不变的量(一般很小)作为 ?的值。
其实熟悉机器学习的同学应该发现了,此处的步长和ML中的学习率非常类似,而随着机器学习的发展,业内也提出了一些随着迭代次数动态变化步长的方法,本文就懒得写了=_=了,感兴趣的同学可以看看我之前的拙笔:
锦恢:机器学习笔记:学习率的调整与实现精确线搜索的方法比较局限,只适用于能够得到? 的迭代过程。不过一般的研究都是从简单的函数开始的,继而启发之后的奇思妙想的,对吧?
所以我们可以研究研究简单的函数在梯度下降法中的精确线搜索。下面我们可以研究研究简单的函数正定二次型:
其中? 是?
维列向量,
?是实对称正定矩阵,
?是与?
维度相同的列向量,
?是实数。
我们记 ?。当我们已经得到
?时,就可以开始在?
的方向上实施精确线搜索,从而得到最优步长?
了:
注意到上述函数是关于 ?的二次函数,故最优步长?
为:
因此在对正定二次型做梯度下降时,通过上述上述的精确线搜索得到最优步长后,更新迭代式为:
那么,对于正定二次型来说,其精确线搜的梯度下降法便得到了:
好吧,让我们假设这个方法能够收敛到真实的全局最小值,且在任意给定的初始迭代点,这个优化方法都能确保迭代序列最终收敛到全局最小值点(也就是梯度下降法具有全局收敛性),我想在下一篇文章中论述梯度下降法的全局收敛性和收敛速率。此处先假设我们的方法可以达到预期的效果。
那我们可以使用Python的numpy和matplotlib子库来编程实现对正定二次型函数使用精确线搜索的梯度下降法,并将搜索过程可视化:
假设我们需要优化的目标如下:
先引入需要的库:
import numpy as np
import matplotlib.pyplot as plt我们需要申明函数中的? 还有原本的函数?
和函数梯度
?的映射
func和gradient。
直接拿之前的作业代码了,懒得把注释写成中文了=_=
Q = np.array([[10, -9], [-9, 10]], dtype="float32")
b = np.array([4, -15], dtype="float32").reshape([-1, 1])
# function and its gradient defined in the question
func = lambda x: 0.5 * np.dot(x.T, np.dot(Q, x)).squeeze() + np.dot(b.T, x).squeeze()
gradient = lambda x: np.dot(Q, x) + b为了检验迭代点的可靠程度,我们需要先计算出这个二次型的最优点:
于是,我们可以申明这个最优点:
x_0 = np.array([5, 6]).reshape([-1, 1])然后编写精确线搜的梯度下降法:
# GD algorithm
def gradient_descent(start_point, func, gradient, epsilon=0.01):
"""
:param start_point: start point of GD
:param func: map of plain function
:param gradient: gradient map of plain function
:param epsilon: threshold to stop the iteration
:return: converge point, # iterations
"""
assert isinstance(start_point, np.ndarray) # assert that input start point is ndarray
global Q, b, x_0 # claim the global varience
x_k_1, iter_num, loss = start_point, 0, []
xs = [x_k_1]
while True:
g_k = gradient(x_k_1).reshape([-1, 1])
if np.sqrt(np.sum(g_k ** 2)) < epsilon:
break
alpha_k = np.dot(g_k.T, g_k).squeeze() / (np.dot(g_k.T, np.dot(Q, g_k))).squeeze()
x_k_2 = x_k_1 - alpha_k * g_k
iter_num += 1
xs.append(x_k_2)
loss.append(float(np.fabs(func(x_k_2) - func(x_0))))
if np.fabs(func(x_k_2) - func(x_k_1)) < epsilon:
break
x_k_1 = x_k_2
return xs, iter_num, loss函数准备好后,我们假设此处的迭代初值为? ,进行梯度下降法,并可视化迭代过程:
x0 = np.array([4,4], dtype="float32").reshape([-1, 1])
xs, iter_num, loss = gradient_descent(start_point=x0,
func=func,
gradient=gradient,
epsilon=1e-6)
print(xs[-1]) # last point of the sequence
plt.style.use("seaborn")
plt.figure(figsize=[12, 6])
plt.plot(loss)
plt.xlabel("# iteration", fontsize=12)
plt.ylabel("Loss: $|f(x_k) - f(x^*)|$", fontsize=12)
plt.yscale("log")
plt.show()out:
[[4.999424]
[5.998852]]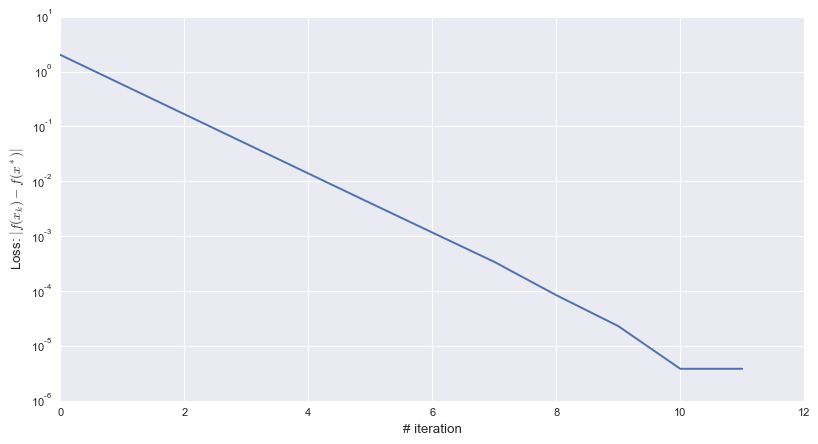
可以看到最终迭代点到达了目标? 。当纵坐标取
?时,收敛速率几乎是线性的。这些都说明了梯度下降法用于优化貌似是可行的,而且还有不错的收敛速率(很快)。
收敛速率定义为?,其中?
是真实的最优点
但是一切都不能高兴得太早。我们可以多试几组不同的迭代初值,然后看看结果会怎么样。我们再取四个迭代点:? 。
# create the list of all starting point x_0
starting_points = [np.array([num, 0]).astype(np.float).reshape([-1, 1]) for num in [0.0, 0.4, 10.0, 11.0]]
plt.figure(dpi=150)
xss = []
# implement GD
for idx, start_point in enumerate(starting_points):
xs, iter_num, losses = gradient_descent(start_point, func, gradient, epsilon=1e-6)
target_point = xs[-1]
xss.append(xs)
# plot the losses of $|f(x_k) - f(x^*)|$
plt.plot(np.arange(len(losses)), np.array(losses), label=f"start point: ({start_point[0][0]},{start_point[1][0]})")
loss = np.fabs(func(target_point) - func(x_0))
print(f"{idx + 1}: start point:{np.round(start_point, 5).tolist()}, "
f"point after GD:{np.round(target_point, 5).tolist()}, "
f"loss:{np.round(loss, 16)}, # iterations:{iter_num}")
print("-" * 60)
plt.grid(True)
plt.legend()
plt.xlabel("# iteration", fontsize=12)
plt.ylabel("Loss: $|f(x_k) - f(x^*)|$", fontsize=12)
plt.yscale("log")
plt.title("Loss-iteration given to different starting points of GD", fontsize=18)
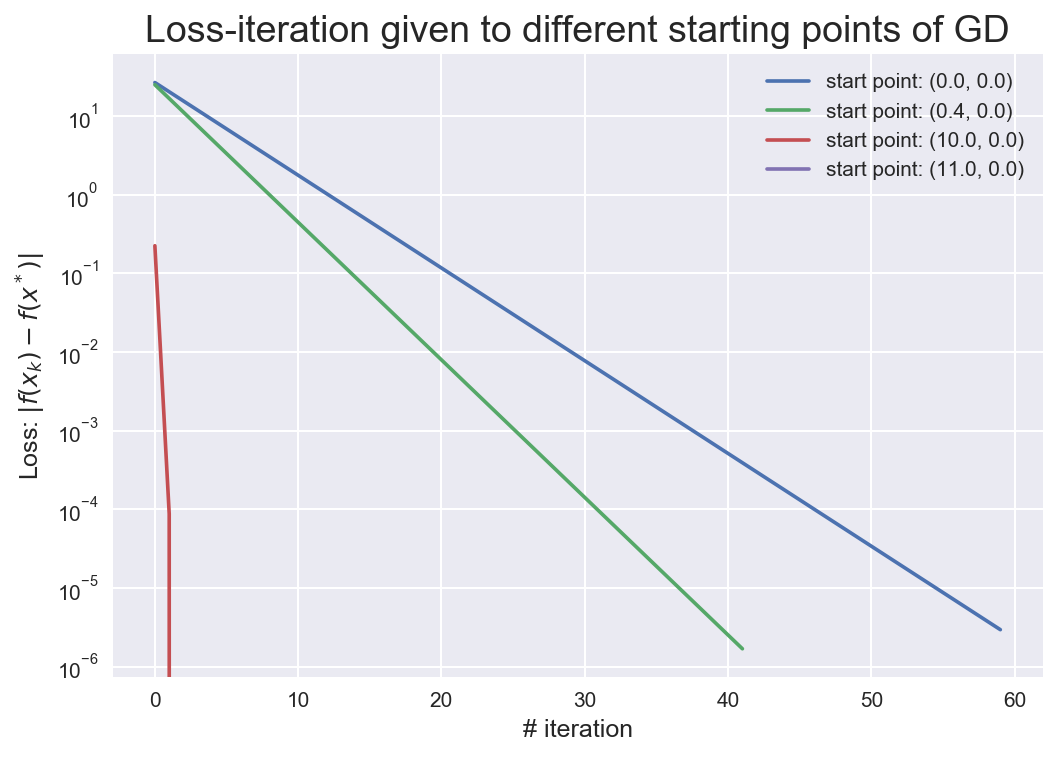
plt.show()out:
1: start point:[[0.0],[0.0]], point after GD:[[4.99855],[5.99826]], loss:2.9518850226e-06, # iterations: 60
------------------------------------------------------------
2: start point:[[0.4],[0.0]], point after GD:[[4.99902],[5.99873]], loss:1.6873629107e-06, # iterations: 42
------------------------------------------------------------
3: start point:[[10.0],[0.0]], point after GD:[[5.0],[6.0]], loss:1.33369e-11, # iterations: 4
------------------------------------------------------------
4: start point:[[11.0],[0.0]], point after GD:[[5.0],[6.0]], loss:0.0, # iterations: 1
------------------------------------------------------------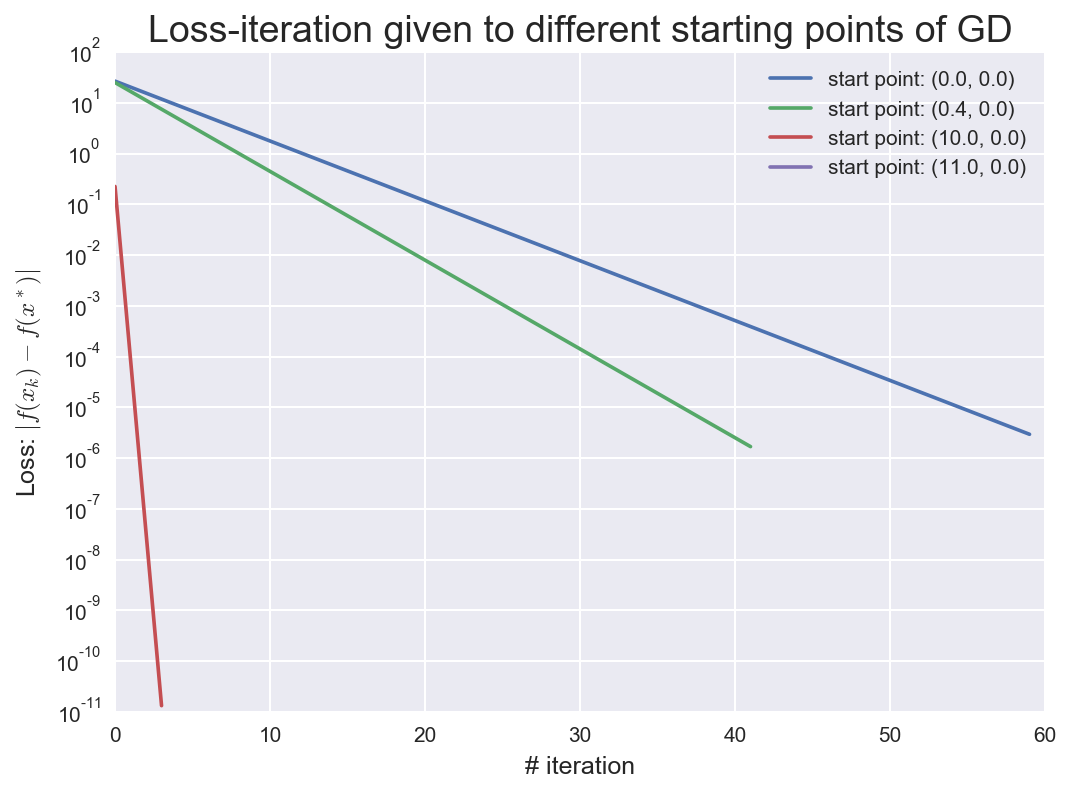
可以看到,虽然对于不同的初值点,其收敛速率都是线性的,但是随着迭代初值的不同,收敛速率不相同。甚至对于? 来说,直接一步迭代就直接到了最优点。
为了更好地让读者明晓迭代初值对于过程的影响,我们可以把上述过程在二维平面内可视化出来:
plt.figure(dpi=150)
X = np.linspace(-2, 12, 200)
Y = np.linspace(-2, 12, 200)
XX, YY = np.meshgrid(X, Y)
Z = [func(np.array([XX[i, j], YY[i, j]], dtype="float32").reshape([-1, 1])).tolist() for i in range(200) for j in range(200)]
Z = np.array(Z).reshape([200, 200])
plt.contourf(XX, YY, Z, cmap=plt.cm.BuGn)
plt.annotate(f"$(5.0, 6.0)$",
xy=(5, 6),
xytext=(5 - 2, 6 + 2),
arrowprops={
"color" : "black",
"shrink" : 0.1,
"width" : 0.6
})
# plot the scatter
for idx, start_point in enumerate(starting_points):
xx = [xss[idx][i][0] for i, _ in enumerate(xss[idx])]
yy = [xss[idx][i][1] for i, _ in enumerate(xss[idx])]
plt.plot(xx, yy, "o--", label=f"start point: ({start_point[0][0]},{start_point[1][0]})")
# add some tips for start point
plt.annotate(f"$({start_point[0][0]},{start_point[1][0]})$",
xy=(start_point[0][0], start_point[1][0]),
xytext=(start_point[0][0] - 1.5, start_point[1][0] + idx + 2),
arrowprops={
"color" : "black",
"shrink" : 0.1,
"width" : 0.6
})
plt.grid(True)
plt.title("Line Search For Two-dimensional Diagrams", fontsize=18)
plt.xlabel("$x_1$", fontsize=12)
plt.ylabel("$x_2$", fontsize=12)
plt.legend()
plt.show()out:
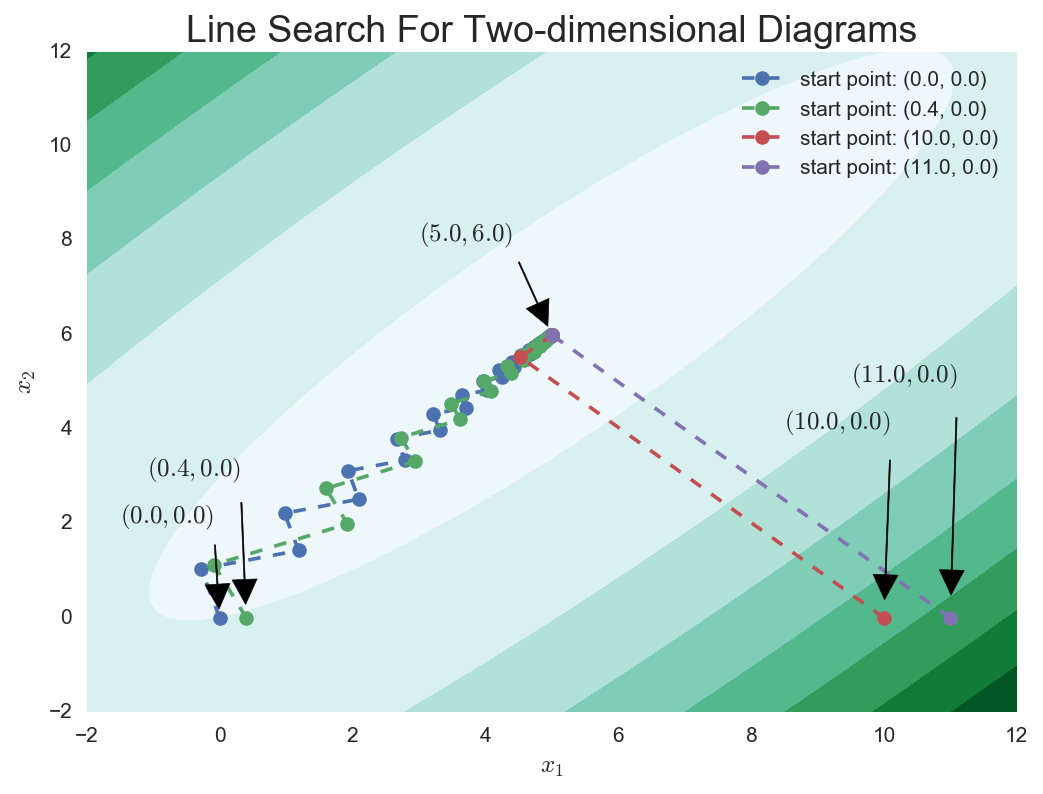
可以看到靠近椭圆(等高线是一个椭圆族)的? 和?
是以锯齿状的轨迹蛇形靠近最优点的,而?
和
?则是几乎一步就跳到了最优点旁边。这张图就很好解释了为什么四个迭代点的迭代步数相差那么大了。
事实上,从我们最开始推导梯度下降法时,我们在某一迭代点处选择最优的下降方向就有一定的问题:我们只追求了 的最大,也就是该点下降“最陡”的方向,但是最陡可不意味着一定能下降得最多,毕竟所谓的“最陡”也只是
这一点的小领域内的最陡,超出这个小领域可就不生效了。而且加上精确线搜的要求,使得整个算法变得很不灵活,因为程序会每步都强行找到
的最小值。这也就使得精准线搜索的梯度下降法在一些稍显复杂的函数优化问题上会迭代非常多的步骤才能找到最优点,甚至有时还找不到。
比如还是拿简单的二次型来说,随着条件数(条件数 大小为矩阵
的最大特征值与最小特征值的比值)的增大,等高线的椭圆族会越来越扁,那么靠近椭圆长轴的迭代初值迭代到最优点会更加困难;或者说,精确线搜的梯度下降法的迭代次数会对迭代初值的选取越来越敏感。这可不是我们希望的,毕竟实际工程中,迭代点的选取很多情况下都是随机的。
读者可是尝试修改上述二次型的的条件数
的大小,看看会有什么变化
既然梯度下降法并不是下降幅度最大的方法,那么很多时候我们也没有必要花大力气把最优的迭代步长找到,找到一个差不多的就行。于是乎,引出下面的非精确线搜。
之前的精确线搜索就是解决单变量问题
的精确极小值点。
这么做不仅计算量大,而且很多时候过于精确的迭代过程也没有必要。因此,我们可以在保证函数下降的前提下放宽对? 的要求,从而降低算法的时间复杂度。
基本思路:通过迭代点处引出的两条直线来约束一段可供?取值的区间,具体可以看如下的图:
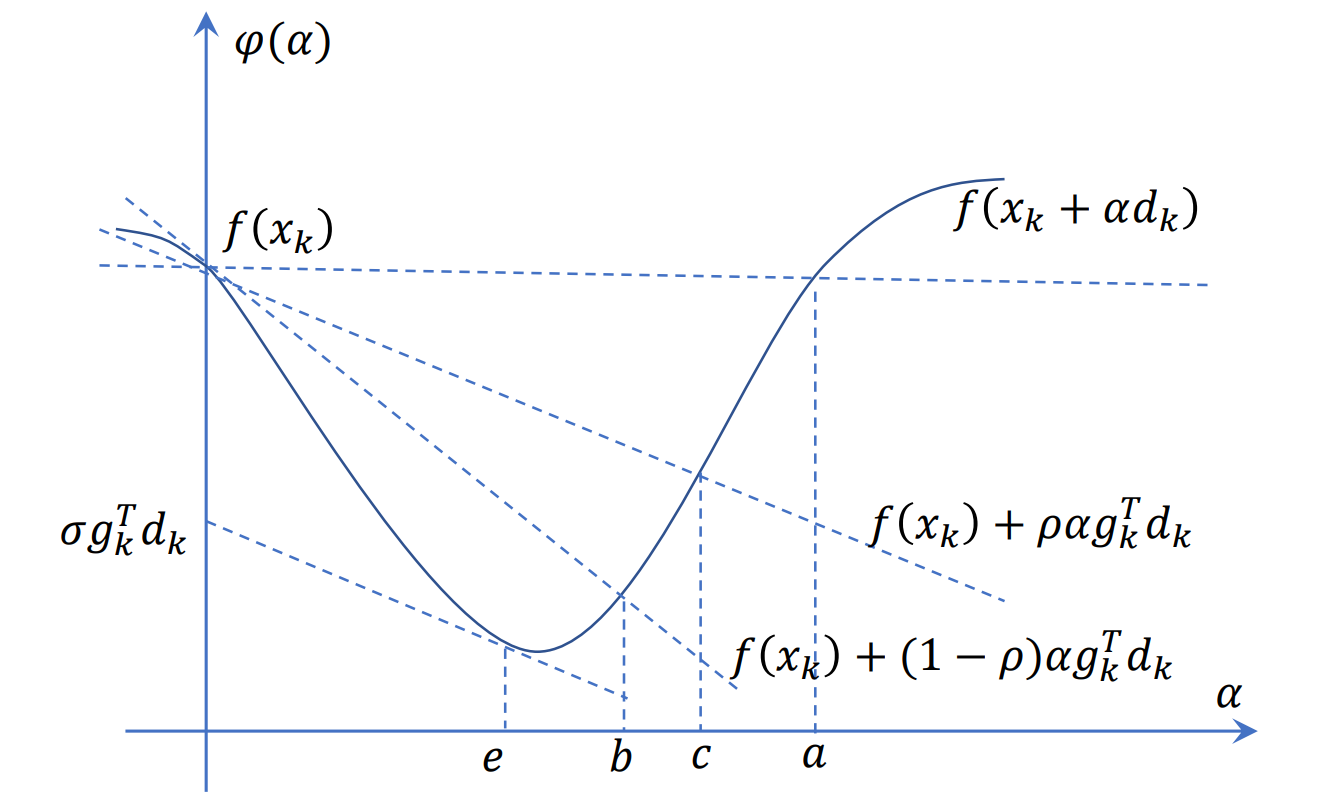
从 处引出的两条射线,我们希望我们选取的
于原单值函数上的映射值位于
在这两条直线上的映射值之间,由是构成它们约束的区间
,那么这一步我们要寻找的步长
就位于
之间。
这两条线的构成的约束也很好写,设 ,则上述两条线的约束可写成:
其中
.
结合上图可知,满足①式的 构成区间
,而满足②式的
构成区间
,因此两个式子构成的约束为
。
其实取这两条直线构成约束的原因也很简单:
于是,我们可以根据①②式得到 Goldstein准则非精确先搜索算法:
算法本身就是通过二分法来搜寻
Goldstein准则有一个很大问题,就是其约束的区间内可能没有我们最终想要找的最优点。
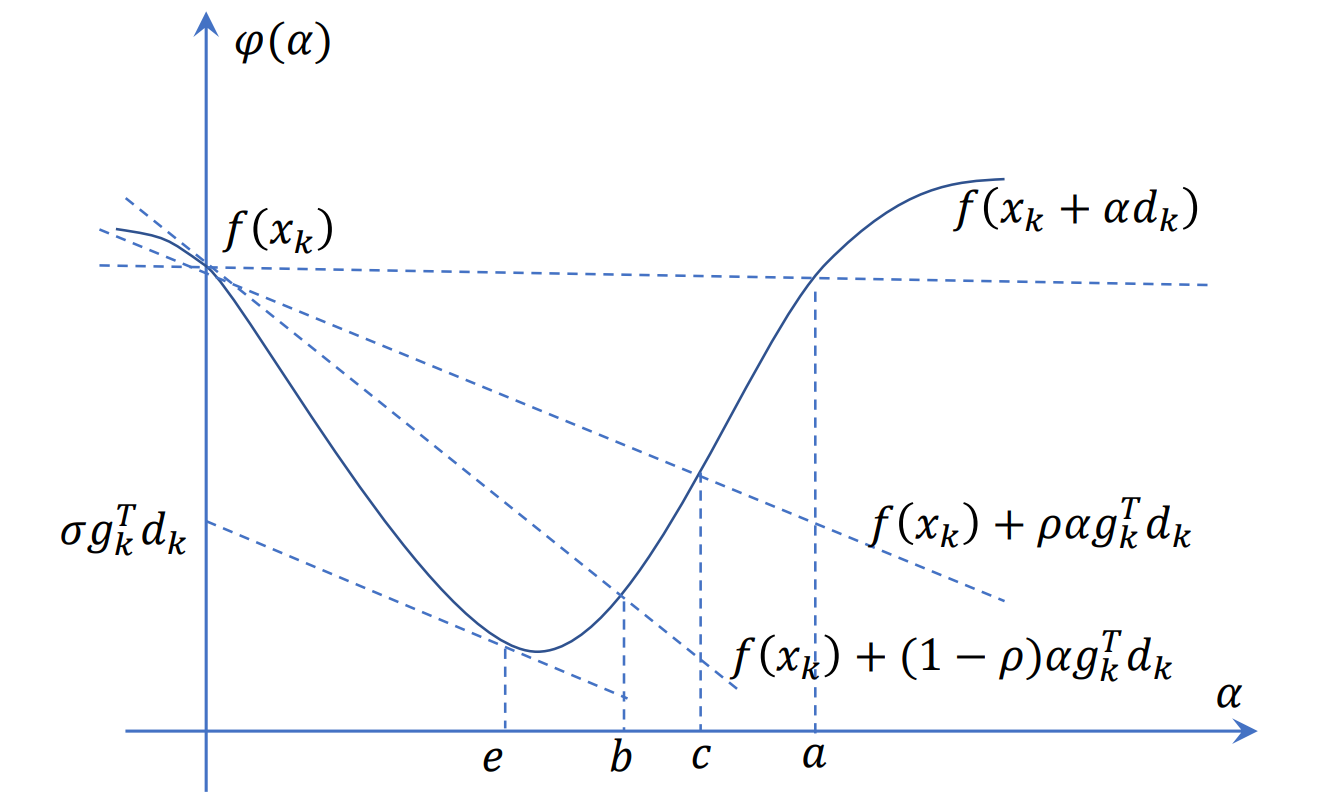
还是刚才那张图,极小值点 ?在?
之间,但是该步确定的区间却为
?,很显然
?。为了克服Goldstein算法的缺点,Wolfe提出了使用以下的条件来代替Goldstein中的②式:
也就是
几何解释:上述条件刻画了在可接受点处切线的斜率?大于或者等于初始斜率的?
倍(注意初始斜率小于0)。在图中,这个切点与起始点都在极值点的同侧,因此这个条件直观上可以保证将极值点包裹在约束的区间内。这个条件也叫作曲率条件。
因此,我们得到了Wolfe准则:
应该指出,由于?
且?
,而精确线搜索的
?满足?
,所以Wolfe准则实际上是对精确线搜索的近似。但是需要注意的是,既然Wolfe准则是对精确线搜索的近似,我们希望搜索出的?
满足如下:
这样做的话当?
时,根据夹逼准则,就会有
?,这样就满足真正的近似了。而我们之前的Wolfe准则得到?不一定小于0.
而满足上述更强的约束条件的准则就是强Wolfe准则。
强Wolfe准则在Wolfe准则的基础上将? 约束到小于0,以确保完成真正的对精确线搜索的近似:
其中
?.
我们注意到 ?的大小在一定程度上决定了搜索出来的
?离极值点?
有多近。?
越小,搜索出的?
越精准,但是计算量更大(因为?
越小,符合要求的
?组成的区间也会越小,搜索目标小区间当然比搜索大的更加费时)。因此,强Wolfe准则的?不能取得太小,否则强Wolfe准则下的非精确线搜索不就和精确线搜索没有区别了吗?
一般来说,会取? .
下面直接调用Python的scipy.optimize子库来实现强Wolfe准则:
def gradient_descent_wolfe(start_point, func, gradient, epsilon=1e-6):
"""
:param start_point: start point of GD
:param func: map of plain function
:param gradient: gradient map of plain function
:param epsilon: threshold to stop the iteration
:return: converge point, # iterations
"""
assert isinstance(start_point, np.ndarray) # assert that input start point is ndarray
global Q, b, x_0 # claim the global varience
x_k_1, iter_num, loss = start_point, 0, []
xs = [x_k_1]
while True:
g_k = gradient(x_k_1).reshape([-1, 1])
if np.sqrt(np.sum(g_k ** 2)) < epsilon:
break
alpha_k = linesearch.line_search_wolfe2(f=func,
myfprime=lambda x: np.reshape(np.dot(Q, x) + b, [1, -1]),
xk=x_k_1,
pk=-g_k)[0]
if alpha_k == None:
break
elif isinstance(alpha_k, float):
alpha_k = alpha_k
else:
alpha_k = alpha_k.squeeze()
x_k_2 = x_k_1 - alpha_k * g_k
iter_num += 1
xs.append(x_k_2)
loss.append(float(np.fabs(func(x_k_2) - func(x_0))))
if np.fabs(func(x_k_2) - func(x_k_1)) < epsilon:
break
x_k_1 = x_k_2
return xs, iter_num, lossscipy.optimize封装了许多最优化中的算法,比如Wolfe非精确线搜索算法,后面的共轭梯度法都有对应的API。不了解的同学,可以去看看源代码了解一下。
对于程序的这个片段:
if alpha_k == None:
break
elif isinstance(alpha_k, float):
alpha_k = alpha_k
else:
alpha_k = alpha_k.squeeze()稍作说明。在梯度下降法实施的过程中,随着迭代点逐步收敛到最优点,为了保证函数下降的可行的步长 组成的区间会越来越小。因此,在迭代的结尾时,强Wolfe算法不一定能够找到可行的
,也就是算法无法收敛,如果算法无法收敛,则alpha_k==None。为了程序的鲁棒性,我们需要判断一下,如果alpha_k==None,则说明迭代到末尾了,直接break就完事了。
out:
[[4.9999986][5.999999 ]]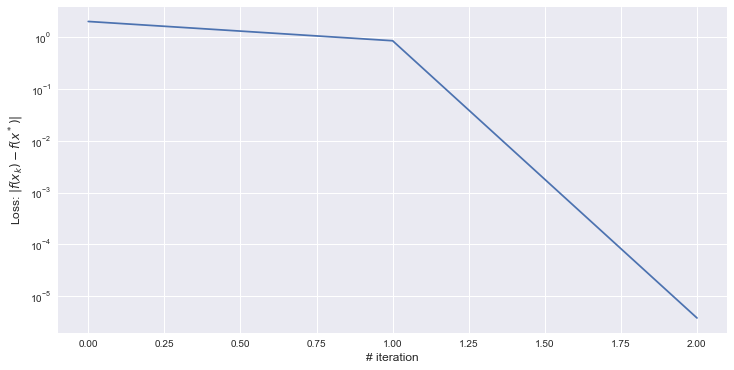
可以看到非精确线搜刚开始貌似下降缓慢,但整体还是保证了纵坐标取 后的线性下降速率。
同上,使用 和
作为四个迭代初值,对这四个迭代初值使用强Wolfe非精确线搜索的梯度下降,打印结果,并可视化:
# create the list of all starting point x_0
starting_points = [np.array([num, 0]).astype(np.float).reshape([-1, 1]) for num in [0.0, 0.4, 10.0, 11.0]]
plt.figure(dpi=150)
xss = []
# implement GD
for idx, start_point in enumerate(starting_points):
xs, iter_num, losses = gradient_descent_wolfe(start_point, func, gradient, epsilon=1e-6)
target_point = xs[-1]
xss.append(xs)
# plot the losses of $|f(x_k) - f(x^*)|$
plt.plot(np.arange(len(losses)), np.array(losses), label=f"start point: ({start_point[0][0]},{start_point[1][0]})")
loss = np.fabs(func(target_point) - func(x_0))
print(f"{idx + 1}: start point:{np.round(start_point, 5).tolist()}, "
f"point after GD:{np.round(target_point, 5).tolist()}, "
f"loss:{np.round(loss, 16)}, # iterations:{iter_num}")
print("-" * 60)
plt.grid(True)
plt.legend()
plt.xlabel("# iteration", fontsize=12)
plt.ylabel("Loss: $|f(x_k) - f(x^*)|$", fontsize=12)
plt.yscale("log")
plt.title("Loss-iteration given to different starting points of GD", fontsize=18)
plt.show()out:
1: start point:[[0.0],[0.0]], point after GD:[[4.99855],[5.99826]], loss:2.9518850226e-06, # iterations: 60
------------------------------------------------------------
2: start point:[[0.4],[0.0]], point after GD:[[4.99902],[5.99873]], loss:1.6873629107e-06, # iterations: 42
------------------------------------------------------------
3: start point:[[10.0],[0.0]], point after GD:[[5.0],[6.0]], loss:0.0, # iterations: 3
------------------------------------------------------------
4: start point:[[11.0],[0.0]], point after GD:[[5.0],[6.0]], loss:0.0, # iterations: 1
------------------------------------------------------------
plt.figure(dpi=150)
X = np.linspace(-2, 12, 200)
Y = np.linspace(-2, 12, 200)
XX, YY = np.meshgrid(X, Y)
Z = [func(np.array([XX[i, j], YY[i, j]], dtype="float32").reshape([-1, 1])).tolist() for i in range(200) for j in range(200)]
Z = np.array(Z).reshape([200, 200])
plt.contourf(XX, YY, Z, cmap=plt.cm.BuGn)
plt.annotate(f"$(5.0, 6.0)$",
xy=(5, 6),
xytext=(5 - 2, 6 + 2),
arrowprops={
"color" : "black",
"shrink" : 0.1,
"width" : 0.6
})
# plot the scatter
for idx, start_point in enumerate(starting_points):
xx = [xss[idx][i][0] for i, _ in enumerate(xss[idx])]
yy = [xss[idx][i][1] for i, _ in enumerate(xss[idx])]
plt.plot(xx, yy, "o--", label=f"start point: ({start_point[0][0]},{start_point[1][0]})")
# add some tips for start point
plt.annotate(f"$({start_point[0][0]},{start_point[1][0]})$",
xy=(start_point[0][0], start_point[1][0]),
xytext=(start_point[0][0] - 1.5, start_point[1][0] + idx + 2),
arrowprops={
"color" : "black",
"shrink" : 0.1,
"width" : 0.6
})
plt.grid(True)
plt.title("Line Search For Two-dimensional Diagrams", fontsize=18)
plt.xlabel("$x_1$", fontsize=12)
plt.ylabel("$x_2$", fontsize=12)
plt.legend()
plt.show()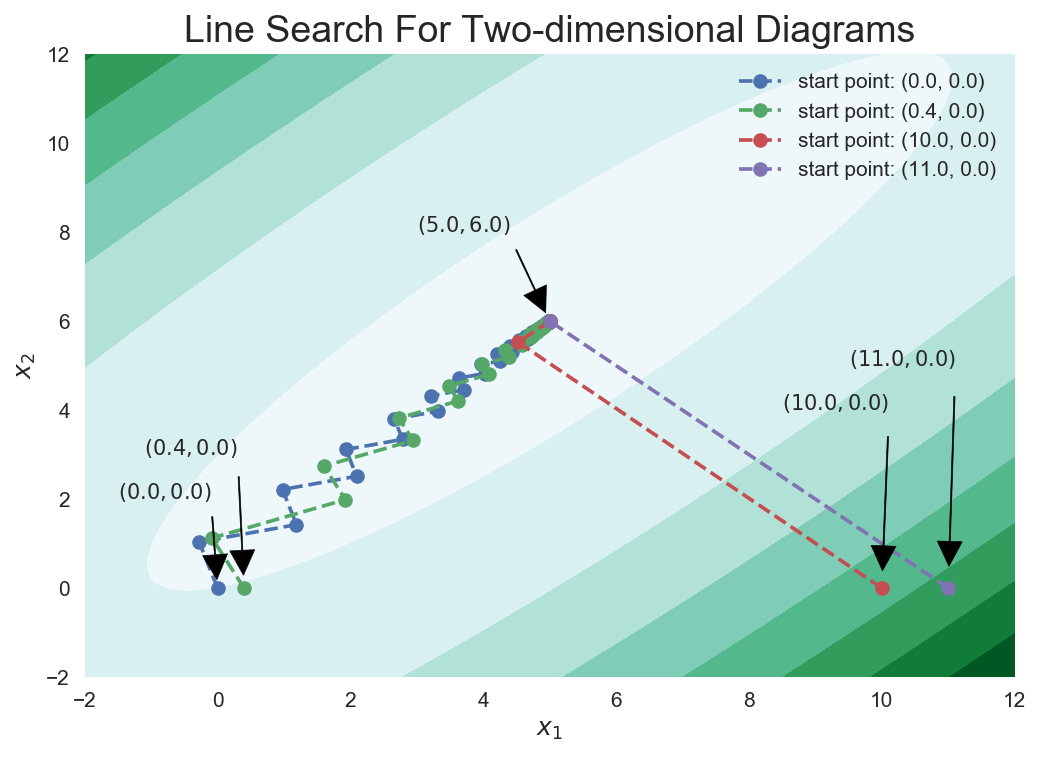
to be continued...
下一章传送门:
锦恢:最优化方法复习笔记(二)梯度下降法的全局收敛与收敛速率






