
北京某某塑料板材有限公司
诚信 / 务实 / 完善 / 快速 / 放心 - 国际品牌
咨询热线: 020-88888888
当前位置: 主页 > 资讯中心 > 常见问题 » 目前有没有可以 AI 实现自动绘画的软件?

具体意思是:“上传一张(或几张图,)软件可以自动识别绘画风格并模仿该画师的画风来自动绘制”可以自己diy人物动作之类。
(对于原画场景,暂且不考虑
ps:目前我已知的自动上色软件s2p已可以实现全自动上色,网站https://artbreeder.com/可以实现ai捏人,如果想要制作这种软件,目前应该克服的最大问题是什么?怎么渲染 使用什么去实现?(但如果真有的话画师该失业了吧)
你知道制作这个视频背后技术吗?
大谷表示,「使用了开源AI绘画项目Disco Diffusion」。
据大谷介绍,这个视频自己耗时10天才完工。
这期间,大谷全程负责「监工」,盯着AI干活,并提供给AI需要的摄像机镜头位移坐标,补充一点场景文字信息。
到后期再填上字幕和微调剪辑,就完成了这个作品。

而他做这个视频的动机很简单,
想要研究一下AI的绘画潜力怎么样。
那么这个AI作画的能力究竟如何?我们来个「慢镜头」欣赏一下...
「转身那一刻,世界崩落」这句歌词一出,
开场画面中,粉色的童话世界瞬间变成了万丈深渊的魔域世界,让人有一种很大的视觉反差。

?再来看,AI根据歌词「天空如同被雷鸣闪电划破、玫瑰盛开」填画的表现力也很不错。
其中像「闪电」和「玫瑰」这样的关键信息都在画面中生成了。

但是,当你仔细盯着这个动画不要眨眼睛时,是不是真有种自己吃了云南毒蘑菇的感觉。
天旋地转,简直太魔幻了...

?Boom,Boom,Boom,Boom歌词一出,AI作画的风格就很诡异了...
很明显歌词中都在说的是,心跳Boom。
而AI却把炸弹、烟花、气球,白色框框杂糅到一个画面中。

这画风,这调调和整首歌的意境不太相融了。
可以说,AI的智商在理解句子上没问题,而理解整首歌词内涵还是不太够(doge)。
到了最后收尾,AI从前面很有意境的风格转化成了赛博朋克风。
星际飞船、行星、宇宙...

就比如下面这个场景很类似「黑客帝国」中尼奥从母体诞生周围环境的一幕。

可以看到,AI根据输入的文字歌词和场景描述生成了每一帧画面中的世界。
每一幅画面亦真亦幻,似梦非梦。
技术介绍:AI作画「卷」出新高度
在介绍这个工具之前,先来看两张图片。


看完这两张图片,你可能会觉得,这是哪个大牛插画师的作品。估摸着,这么精良的作品,放到市场上卖个几千不是啥大问题。
如果真是大牛画的,那还真没什么亮点了。虽然很好看,但也不是不能完成的。
可如果,这两幅画,还有一大堆别的一样好看的画,都出自AI之手呢?
你会不会觉得不可思议?
真相是:这两幅画的作者都是Liliia Sitailo。准确来讲,Sitailo只负责输入指令,作画部分完全交由AI完成。

如果你让我说,这么完美的构图、清晰的思路,还有身临其境的氛围、抓人眼球的色彩,都是AI完成的,我还真不一定信。
事实证明,这款谷歌开发的名为Disco Diffusion的AI作画工具非常之成功。目前,这个工具已经更新到了第五代,V5版本。
这是一款由谷歌Colab平台开发的,利用人工智能深度学习进行数字艺术创作的工具,基于MIT许可协议,目前已开源。
用户可以在谷歌Drive直接运行。
有了这个工具,不需要用户懂什么构图知识,也不需要有任何艺术细胞,只要想点子就可以了。
另外,大家熟知的DALL-E也同样在4月迎来了更新。
Open AI对画图界的扛把子DALL-E进行了2.0版的全面升级。让自然语言生成图像达到了全新的高度。
比如下面这幅很有穿越感的画。

还有之前占据AI画画老大哥地位的Imagen,做了一副「有点怪,我再看看」的画。

谷歌除了上面提到的Disco Diffusion,最近也有一款名叫Parti的画画AI问世了。
Parti,全名叫「Pathways Autoregressive Text-to-Image」,是谷歌大脑老大Jeff Dean提出的多任务AI大模型蓝图Pathway的一部分。
我们来看看Parti的作品:

看完后,是不是顿时感觉,会画画的AI都这么卷了...
大谷是谁?
提到大谷,你一定会立马想到「AI复活」系的专业户。

大谷1991年生于北京,获得了纽约视觉艺术学院电脑艺术硕士学位。
作为一个艺术家,音乐家,程序员和独立的游戏设计师,生产力真是爆炸。
此前,我们已经看到过很多由他创作的一些作品。
最出名的就是用AI修复100年前老北京影像。发布后,这段修复Vlog爆火,引来许多网友的关注。

另外,像他用AI修复让李大钊、陈延年等老先辈们露出笑容也得到网友一致好评。

还有AI还原宋明清三朝皇帝、泰戈尔、梅兰芳,百年前上海时装秀....

所以说称其为「AI复活专业户」也不为过。
不过,这次大谷却为我们带来了不一样的创作。
已经有很多了,普通人完全可以玩,最近我也在学习研究这方面的工具。
AI绘画大部分人应该还停留在表面理解,它是通过一段关键词输入就能生成关联图像的技术。目前的算法基本上都来自于openai,不同工具因为训练模型和算法的不同,制作的图像差异还是蛮大的,而且我看了很多AI生成的绘画,风格都比较油腻,一看就知道不是人工画的。
列出一些AI绘画的工具:
https://app.wombo.art/比如我输入个吸尘器,加上自己拍过的一个图片,它能快速生成一个融合的AI照片。

入门非常容易的wombo,免费的,但是功能也相对简单。
AI Art Generator, AI Art Maker使用也是比较容易,同样是直接输入关键词就可以,不过生成速度比较慢,要等一段时间:
支持手机的AI绘图工具,有免费版本,出图速度也较慢,有一些风格和模板可以设置。
可以根据自己的图,生成AI修改后的图,且效果不错。

几分钟能出一个这样的效果图,我是非常惊讶的,视觉冲击力很强,而且很细腻。

应该也是目前最火的AI绘图工具了,细分的功能比较强大,入门也相对复杂,需要教程才能顺利上手。有兴趣的可以自己去研究下,国内已经很多人在研究了:

也是比较火的一款工具,看到过一些大神做出来的图,非常精美细腻:


Dalle2
DALL·E 2
其他工具还有很多,也列出一些:
Imagen:
Text-to-Image Diffusion ModelsPytti:
Google ColaboratoryJax clip:
Google Colaboratory对于和我一样的初学者,重在尝试,找到适合自己的工具,也许这是以后对内容工作者,对版权有问题的特别高效有效的工具,而且现在已经有不少人通过AI绘图开始做副业赚钱了,这可能会是未来改变很多行业和个人的一个重要的技术领域。
Part 1 初试
看和菜头玩AI绘图好几个月了,心里痒痒,昨天刚好有空就尝试了下,没想到打开了新的世界,一玩就玩了一天。先给大家看几张刚画的图。



没错,现在AI除了会玩游戏,会写作文,会下围棋,也会画画了。
像我这种不太会画画的人,只要给AI一串指令,AI就能按照我的需求,绘制(生成)相关的图片。
而且图片都是独一无二的,所以不用担心侵权的问题(注意,部分工具对生成图片的版权有限制的除外),发文的配图就不用到处找了,可以节省很多时间。
而且,谁心里还没有个画家梦呢?只要给AI一些文字,就能让它生成你想要的图,听起来是不是很美妙?
如果你也对AI画图感兴趣,那么可以这样,然后那样,最后那样,然后就可以得到一幅好看的图啦。
嘿嘿,开玩笑。
Part 2 步骤
目前最流行的AI绘画工具是Disco Diffusion,今天也顺便分享一下怎么入门画出自己的第一张图吧。
第一步,准备谷歌账号和上网
咱们的AI是需要依托于谷歌的colab平台运行的。所以,你需要有个谷歌账号。而且,还需要有会科学上网。否则只能显示404 not found。
什么,你没有谷歌账号,那就自己注册一下。http://google.com→右上角登录→创建账号就行。
什么,你说不会科学上网,啊这,抱歉我也帮不了你,找朋友问问怎么弄或者网上搜索下试试,不然这个教程后面都不用看了,看了也用不了。
第二步,用谷歌浏览器chrome打开disco diffusion 项目
https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb
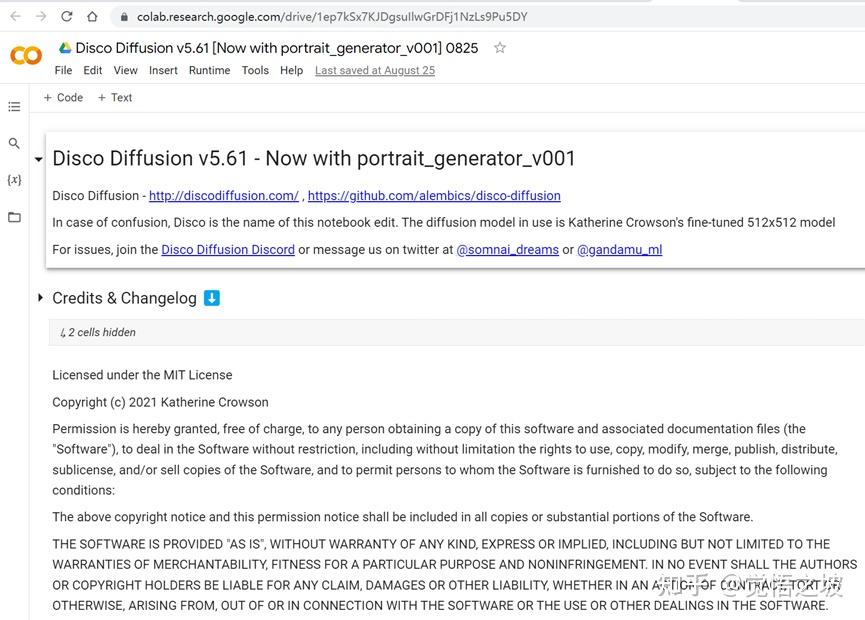
第三步,点击Runtime -> Run all
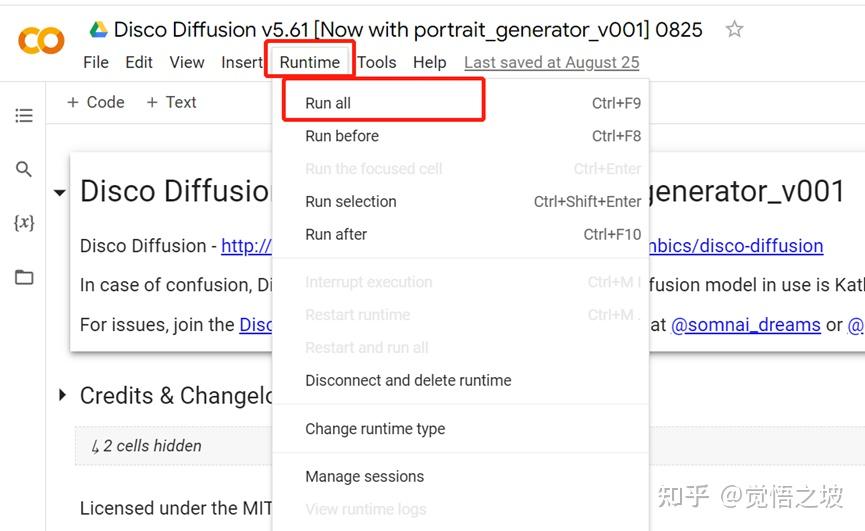
现在,系统会一步一步运行所有代码,包括安装等(从外部安装到你的google drive,非本地电脑系统)。
这时候,可能要求你同意登录谷歌账号,要求谷歌授权访问google drive等等,全部选择同意/仍然运行即可。
系统默认会用默认的Prompts指令,生成一系列的海上灯塔图(50张)。
可以看一下第四部分“Diffuse!”的末尾,如果出现steps进度条,并且进度条上方出现一个大方框,那么,证明你的图片正在生成。

生成一张图片需要10分钟左右(算力紧张的时候可能会稍慢)。
建议你等第一个图片生成完毕之后(也就是上图的顶端Batches从0/50变成1/50之后),再来进行下一步。
第四步,获取刚刚生成的图
可以去http://drive.google.com,也就是google drive → AI → Disco_Diffusion→images_out→TimeToDisco文件夹里面找。
就可以找到刚刚生成的灯塔图

(类似上图,但肯定不是完全和我一样的)
然后可以直接从google drive下载直接使用或者进行二创,都行,随便。
第五步,自定义生成图片
(1)如果你的“4. Diffuse!”->"#@title Do the Run!"左侧不是三角形的播放图标,而是不断转圈的方框停止图标,那么,点击一下他。直到他变成外面是圆形里面是三角形的图标。

(2)“4. Diffuse!”的第一部分的“n_batches”后面的值,把50改成1或者2或者3都行。因为这代表你用同样的设置,需要生成多少张同样类型的图片。因为每张图片可能需要10-30分钟,花太多时间在一个prompt上不一定值得。

(2)更改“3. Settings”里面的“Prompts”模块,更改双引号里面的内容。

比如可以把"A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation", "yellow color scheme”
改成“a detailed matte painting of blue ocean, waves, a black whale flying in the sky, by Caspar David Friedrich, Trending on artstation” (注:prompts来自西乔)
改完之后,prompt左侧的播放图标,点一下他。你会发现它很快转一圈,接着它左侧会变成绿色的对勾,那就代表新的prompt生效了。
接下来,在”4.Diffusion!“的第一部分#@title Do the Run!的左侧,点击黑色的开始按钮。
在”4.Diffusion!“的末尾,就能看着自己的图一步一步生成啦~
生成完可以直接去google drive拿图。
恭喜,现在你已经会使用AI画画了。
只要能生成第一张第二张图,后面的,就是如何调整prompt指令,让AI给你生成不同的图,以及调整DD各种参数,让图片更能按自己想要的效果来展示。
至于怎么调试prompt,或者怎么调试各种AI参数,那就是更高阶的内容了,现在初阶教程先到这里,祝你玩得愉快~
Part 3 其他说明
新手的prompts最好先按照已有的教程prompt去尝试,否则可能生成奇怪(诡异)的图像。
DD对于生物体以及人类的拟合还不是特别好,因此不建议新手在prompt里面写人,比如woman,man之类的,尤其是face正脸什么的。否则,可能会出现一些掉san值的恐怖图片。
最近很火的stable diffusion已经开放公测,用它来画人效果好很多,感兴趣的可以在https://beta.dreamstudio.ai/dream测试使用,比如下图是我画的。

参考资料
《一些Disco Diffusion的资料》-和菜头-槽边往事
《DD Course-01: 从0到1,在浏览器里运行 Disco Diffusion 》西乔-神秘的程序员们
《DD Course-02: Prompt 的构建——图像的作品类型》-西乔-神秘的程序员们
《当下最强的 AI art 生成模型Stable Diffusion 最全面介绍》-西乔-神秘的程序员们
图像来源
Disco Diffusion v5.61
beta.dreamstudio.ai(Stable diffusion)
写在前面:这是今天在中国数据内容大会上的演讲分享。我把内容归纳整理了一下,补充了一些资料,也算是对过去一段时间的回顾。这篇文章可以让大家更好的了解AI绘画如何发展到今天的,作为一个科普文,里面不涉及任何高深的技术点。

AI生成绘画本来是一个特别小众的领域,但是在今年越来越多圈子外的人都已经开始了解和使用它。那么今天我想带大家一起回顾一下AI绘画是如何开始的,又是怎么在今年突然出圈?

我们几乎每个人都会说话,但是只有极少数的一部分人会画画,我们管这一小部分会画画的人叫画师。画画在大家眼里是一件需要天赋和长期艰苦训练的事情,很多人从小就接受美术训练,花了长达7~8年的时间可能才可以达到一个及格的水平。
那么大家有没有想过有一天?只要你会说话,会使用语言,就能够创造出一副画。用语言画画这件事听起来就跟魔法一样,但是它在今年已经通过AI变成了现实。


这件事的源头得从7年前,2015年开始说起,那一年出了一项人工智能的重大进展——智能图像识别。机器学习可以标记图像中的对象,然后他们还学会了将这些标签放入自然语言描述中去。
这件事让一组研究员产生了好奇。如果把这个过程翻转过来会怎么样?

我们可以把图像转换成文字,那么我们是否同样可以把文字转换成图像?
这是一项异常艰巨的工作,它跟你从搜索引擎上用文字搜索图像完全不一样。他们希望用文字去生成那些这个世界上没有的图像。

于是他们向计算机模型询问了一些他们从未见过的东西。举个例子,你见过的所有的校车都是黄色的,那么如果你写红色或者绿色的校车,它真的会尝试生成绿色么?它真的做到了。
这是一个32X32像素的小图片,糊的你几乎分辨不出来这是什么东西,但是这是一切的开始。这些研究人员在2016年的论文显示了未来的无限可能。

而现在未来已来。
如今想要得到一副图像已经可以不通过任何绘画,相机,软件或者代码等工具。你只需要输入一行文字。


让我们把时间倒回去一年,回到2021年一月。一家叫openAI的人工智能公司宣布了dalle,他们声称可以从任何文字中创建图像。他们今年4月公布了dalle2,生成的图像更加的逼真和精确了。而且还可以对这些图像进行无缝编辑。
但是openai一直都没有公开dalle的算法和模型。直到现在,哪怕dalle2都开始商用了,它的限制仍然很多。

所以在过去的一年里,一个由独立开发人员组成的开源社区,根据现有的所有已知的技术模型,做了各种各样的开源文本图像生成器。
在这个时期我把它称之为colab时期,这些免费开源的生成器都需要你在google colab上才可以使用,需要一定程度的代码知识,而且生成的图像还非常的抽象,像素也比较低。我周围也有几个朋友在21年开始玩AI绘画,但是都局限在非常非常小的圈子。
2021年11月的时候一款叫dream by wombo的APP出现了,它把AI的生成器封装到了APP里,这个举动让所有人都可以零学习成本的使用它。所以它从2021年底一直从国外火到了国内。
但是因为模型算法的局限性,它生成的图像质量还是比较低的,但是已经引起了大家的好奇心。

在2022年的2月,由somnai等几个开源社区的工程师做了一款叫disco diffusion的AI图像生成器。从这款图像生成器开始,AI绘画得到了质的飞跃。而且它建立了完善的帮助文档和社群,disco diffusion本身也拥有非常完善强大的功能。

同样是赛博朋克城市的提示词,DD与dream的对比
3月国内开始出现disco diffusion的教程,随着这些教程的不断完善完善。越来越多的人开始使用disco diffusion创作作品,但是DD有一个致命的缺点就是它生成的画面都十分的抽象,这些画面用来生成大场景和抽象画还不错,但是几乎无法生成具象的人或者物。
这个时候一款叫midjouney的AI绘画生成工具出现了。
3月14日,mid开始内测,这是一款由disco diffusion的核心开放人员参与开发的AI生成器,mid与dd不同,它是一款搭载在discord上的聊天机器人程序,不需要之前繁琐的操作,也没有DD十分复杂的参数调节,你只需要向mid输入文字就可以生成图像。而且mid的模型更加的精准,dd只能生成抽象的风景,但是mid在人像上也能表现的比较好。
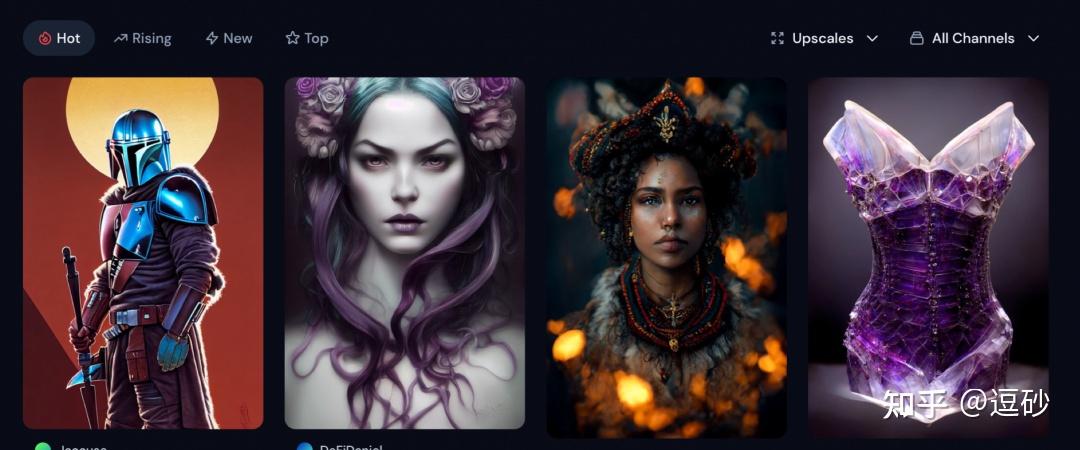
而且midjouney最大的优势其实并不是它的生成效果多么优秀,而是在于它是一个社区形式的产品。跟DD每个人都是独立创作不同,在mid上所有人的作品都是公开的,你用的提示词和相关的作品都是对社区里所有人可见的,你再也不需要问其他人这幅画用了什么提示词?这个特性让社区每天都不断的涌现越来越多优秀的作品和创意,每个人都可以尽情的学习他人的作品。
我把它称之为养蛊式创作。
4月10日,dalle2开始内测,dalle2可以生成非常精确复合逻辑的图像。它还可以根据提示词来重新修改编辑的你图片。我们来看一段dalle2的宣传片。
 https://www.zhihu.com/video/1548416089587146752
https://www.zhihu.com/video/1548416089587146752我们可以从dalle2的宣传片可以看出跟之前的AI生成器都不同,无论是DD还是mid,我们都是可以看出是AI生成的,dalle2的生成图你已经无法跟人类的作品做区分了。
这是我用用dalle2创作的画,是由左边的提示词直接生成的。如果我不做说明,这幅画跟正常的人类作品几乎没有区别。

它还可以直接生成非常有质感的3D图像,这是我用dalle2直接生成的3D金属质感的十二生肖图标。

它还可自动补充无限拓展图像,所以特别适合用来生成无限流动画。类似这种。
 https://www.zhihu.com/video/1548416318306463745
https://www.zhihu.com/video/1548416318306463745看到这里大家可能觉得dalle2已经很完美了,但是其实直到今天,dalle2的相关技术都是对公众封闭的,而且dalle2的使用也需要申请,而且通过率很低。dalle2的研发人员觉得他们做了一款很可能用来作恶的工具,所以它设置了非常多的限制,死亡,色情,人脸,暴力,公众的人物等等都是禁止在dalle2上使用的。
跟openai这个名字不同,dalle2一点都不open。
dalle2的担忧是多余的么?不是的,这个工具确实非常可怕,不法分子可以利用它来轻松生成各种各样的假图片。但是历史的车轮会因为dalle2的这些限制停下来么?
7月29日 一款叫 SD的AI生成器开始内测,它可以生成媲美dalle2的精确度的图像。共分 4 波邀请了 15000 名用户参与了内测。只用了十天它的活跃数据已经到了每天一千七百万张。

SD的背后是一家英国的人工智能方案提供商,它的slogan就是“ai by the people,for the people”。跟dalle2的封闭不一样,这家公司十分推崇开源。
所以在8月22号,他们内测刚开始二十多天,SD正式宣布开源,这意味着所有人都通过它开源的技术,在本地使用SD生成自己想要的图像。SD开源属性让它在短短的一个月跟各种各样的工具结合。甚至mid也使用了开源的sd模型,并且得到了巨大的反响,这个功能只内测了24小时,但是是目前mid社区里呼声最大的。24小时里mid结合SD生成了大量的作品。

国外艺术家用SD生成的画作,艺术效果上已经超越了dalle
除此之外它还被做成了figma和ps的插件,在figma的插件里你只需要简单的画出草图,就能根据文字生成非常完整的设计稿。在ps里面你可以无缝拼接补完图像。可以说现在的SD把前面所有的AI生成工具的功能全部结合到了一起,然后还把它开源了。
被做成figma插件的SD

现在,我们来回顾一下这一切,2015年的时候,一群好奇的工程师,把图像识别生成文字这个过程翻转过来了,他们生成了最开始的32像素的小图片,在经过了漫长的六年的缓慢发展后,2021年openai和一群开源工程师分别用他们自己的方式完善算法和模型。到了今年2022年,这个技术突然就爆发了,对于国内的大部分接触AI绘画人来说只有短短的四个月,这四个月里发生了mid内测,mid公测,dalle2内测,dalle2商用,sd内测,sd开源等等,还有无数的AI绘画小工具。
哪怕是像和菜头这样完全绘画圈外的人也在不断的讨论和使用AI绘画的功能。
很多创意相关的人已经开始用AI辅助了,我的一个朋友说,他的老板让他不要对外说他们的工作中加入了AI辅助。
“不要跟别人说我们的工作中使用了AI辅助。”
现在已经有大量的创意人和公司在使用AI绘画辅助,但是他们又不希望有太多的人知道。还有大量的创意与艺术行业的从业者内心十分抵触这项技术,觉得它根本就不应该出现。在8月15号就发生过一件非常有趣的事件,SD的推特账号突然挂了,因为被大量艺术家举报,SD的创始人在社群里表达了他对这件事的看法,他说:他们在嫉妒AI画的比他们好。不过这件事最后被证实为乌龙,因为这个账号其实只是个粉丝账号,并不是官方账号。
历史的车轮呼啸而过,是选择跳上这辆车,还是停留在原地,都是个人的选择。但是无论你是否参与,它都不会因为你的看法而停下来。
最近真的好焦虑呀,各种 AI 工具的横空出世,感觉分分钟就要失业……但与其焦虑被 AI 替代,不如积极探索如何用好这些工具。作为影视广告领域的老司机,除了关注 ChatGPT 能怎么帮我写视频脚本开拓思路外,最关注的当然还是视觉领域的 AI 绘画大神 Stable diffusion 和 Midjourney。

通过这段时间的摸索,我将和你探讨,对普通人来说,Stable diffusion 和 Midjourney 怎么选?最重要的是,学好影视后期制作对 AI 绘画创作有哪些帮助?反过来,AI 绘画对影视后期又有哪些帮助?
先说第一个问题的结论:普通人请直接选择 Midjourney。

对于咱们普通的小伙伴来说,Stable diffusion 和 Midjourney 两个 AI 绘图软件来说确实有点「老虎,老鼠傻傻分不清楚」。不用怕,通过下面几个方面对比,你基本上就知道它们两者的区别:
易用性
Stable Diffusion 因为是本地部署,所以对关键词没有限制。但提示词门槛高,需要用户有一定的语言基础,对于普通人来说,特别是英语不好的普通人,几次玩下来没有达到理想的效果就很容易放弃;

Midjourney 虽然对敏感词有限制,但提示词门槛低,即使中文通过机器翻译的英语单词也能很好的识别,出图速度也快。就算没有很精细的描述,Midjourney 也能出精细的图,甚至你发两个 emoji 表情包也能生成出大片。

费用
Stable Diffusion 本地或云端部署,基本免费。
Midjourney 为线上使用,每月 10 美刀起~~~~~~
看完以上内容,你是不是已经朝 Midjourney 翻了个白眼,对 Stable Diffusion 充满了期待,并大喊快到怀里来?
且慢!
Stable Diffusion 虽然免费且生产的图片质量更好,但这一切都建立在需要自己部署的基础上……无论是本地电脑部署,还是云端部署,整个过程复杂得一批!这就好比你想要一台性能更好的电脑,于是你开始研究 CPU 参数、显卡参数、主板、硬盘、内存……看到那一大推天书一样的参数和操作步骤,瞬间流下没有技术的泪水!!
不仅如此,你以为本地部署就是有台电脑有手就行吗?No!AI 绘图因为涉及到大量的运算,因此对电脑的配置要求非常……非常……高,否则分分钟崩掉~~~~~特别是对显卡,如果你是 PC 用户,最好是 NVIDIA,且推荐 3080 4G 显存,如果你是 Mac 用户,至少也得是 M1 芯片。现在,让我们来看看价格……瞬间流下了贫穷的泪水 o(╥﹏╥)o

现在,Midjourney70 几块钱一个月是不是瞬间变得也能接受了!!!!只需要下载一个 Discord,绑定好 Midjourney 后就能直接在电脑和手机上像聊天一样使用。是的,在手机上也可以使用。

你可以简单的把 Stable Diffusion 理解为手动挡的专业单反相机,而 Midjourney 则是一个人人抬手就能拍照的傻瓜相机。所以,对于普通人来说,初次尝试 AI 绘画,建议直接使用 Midjourney,当你真的觉得其对你生活和工作有帮助,愿意更深入的去学习和研究,再使用 Stable Diffusion 也不迟。
那么问题来了,学好影视后期制作对 AI 绘画创作有哪些帮助?
AI 绘画的本质其实就是视觉传达,而视频的本质也是视觉传达,所以它们之间有很多共通的底层原理,所以,学好影视后期可以帮你更好的掌握 AI 绘画工具。
说了这么多,使用 Midjourney 究竟应该如何开始呢?如何系统性的学习 Midjourney 创作相关知识呢?好消息是,非常具有前瞻性的知乎知学堂,在 0 基础影视后期剪辑课的正式课程中,不仅包含了视频拍摄前期摄影、摄像、灯光等方面的知识,还加入了长达 5 天的 Midjourney 课程。这绝对不是浅尝辄止,而是手把手教你会使!
但课程虽好,你千万别急着报!知乎知学堂的老师就是怕你冲动消费,所以专门在正式课程前推出了 0.1 元的体验课程。别看只有 2 天,但老师讲的干货非常多!体验课程不仅涉及到影视后期剪辑中最重要的整体思维和总分思维,还有色彩心理学在视频中的应用,以及 PR 剪辑的入门操作。最重要的是,第二天课程不仅教你如何通过短视频变现,还为听完课的同学赠送 280 款 LUT 调色滤镜和 1000 款音效库,手把手领你上路,价值远远超过 0.1 元,快去领取吧~
帮助比如以下四项:
1、 摄像机角度、镜头焦段、景别和景深;
无论是绘画、摄影还是拍摄视频,创作者都会面临这个选择:我应该选用什么样的角度,用什么样的景别,如何构图取景,是否需要景深等。在使用 Midjourney 绘画的过程中,我们会通过英文关键词的描述来确定想要的结果主体以什么样的角度、景别和景深等呈现。因此,会摄影、摄像的人,会更容易让 Midjourney 画出自己想要的内容。

2、 摄影风格、绘画风格、建筑风格和艺术家;
如果你不是艺术家或艺术类专业的学生,你可能很难想象世界上有那么多种摄影风格和绘画艺术风格,而我们可以通过关键词,让 Midjourney 直接绘制你想要风格的内容。而常用艺术风格本身就是一个影视后期人员应该掌握的,哪怕你不会做,至少你知道这是一种什么风格,比如赛博朋克风格、蒸汽波风格、波普风格等等。


3、 灯光效果
我们常说,摄影是光影的艺术,而电影追求的则是声光刺激,都跟光离不开。如何布光是影视工作者的基本功,知道各种不同的灯光类型和布光手法,可以帮助我们营造出不同的氛围。而这个知识点同样可以应用在 Midjourney 中!

4、 物体材质
不同的物体拥有不同的材质,但同样的物体也可以有不同的材质,比如我们可以绘画铜像,也可以绘画石像,所以对材质的掌握也是使用 Midjourney 不可缺少的一步。恰好,对于影视后期来说,特别是影视后期中的三维建模、特效师来说,不同材质的不同特性早已烂熟于心,而他们只需要输入相应的关键词就可以在 Midjourney 中得到非常不错的主体。

所以你看出来了吗?想要完全掌握未来的 AI 绘图工具,摄影、摄像、后期特效的知识必不可少,它们就是地基。而 AI 绘图还只是人工智能创作的第一步,AI 视频生成已经在来的路上…………
最后,我们都很好奇,掌握影视知识可以帮助我们快速更好使用 Midjourney,那 Midjourney 可以如何帮助我们更好的做好视频呢?
由于目前 Midjourney 主要以生成图片为主,因此它可以帮助我们在前期把剧本、故事等绘制成直观的分镜头,再也不怕手残啦!另外,无论你是想实景拍摄还是做后期特效,通过 Midjourney 生成场景,可以为我们提供灵感,特别是去尝试那些我们从来没试过的风格,也许会有意想不到的发现!

原文作者:仙人球球
目前,该付费内容的完整版仅支持在 App 中查看
App 内查看






