
北京某某塑料板材有限公司
诚信 / 务实 / 完善 / 快速 / 放心 - 国际品牌
咨询热线: 020-88888888
当前位置: 主页 > 资讯中心 > 公司新闻 » CNN的优化器与学习率的总结,以MNIST数据集训练为例

本文是在pytorch环境下对基础的四种优化器进行一些直观比较与分析,同时在固定使用使用Adam优化器时对不同学习率进行了分析。
为了将各个优化器的不同性能更直观的反应出来,我们将Mnist数据集输入CNN,并使用不同优化器对数据集进行训练,将最终的损失函数对比,可以明显看出各个优化器的特点。
首先,我们先了解一下Mnist数据集:
MNIST 数据集来自美国国家标准与技术研究所, 由来自 250 个不同人手写的数字构成,它的获取方式为: http://yann.lecun.com/exdb/mnist/
它包含了四个部分:
从名称可以直观看出,Mnist数据集主要分为训练和测试两个部分,每个部分都有图片和标签,一张图片对应一个标签。图片是以字节的形式进行存储, 我们需要将原有数据进行预处理:
Step1 将原数据转成张量(tensor)类型
Step2 用平均值和标准偏差归一化张量图像
#预处理代码:
# 数据集的预处理
data_tf=torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor( ),# 将原有数据转化成张量图像,值在(0,1)
torchvision.transforms.Normalize([0.5],[0.5])# 将数据归一化到(-1,1)
]
)
#数据集导入与迭代数据的获取:
# 数据集获取路径设置
data_path=r'D:\\my_data\\MNIST100Collection\\Datasets'
# 数据集的获取
train_data=mnist.MNIST(data_path,train=True,transform=data_tf,download=False)
test_data=mnist.MNIST(data_path,train=True,transform=data_tf,download=False)
# 获取迭代数据
train_loader=data.DataLoader(train_data,batch_size=64,shuffle=True)# 训练数据,batch用于一次反向传播参数更新
test_loader=data.DataLoader(test_data,batch_size=100,shuffle=True)# 测试数据,shuffle是打乱数据的意思(多次取出batch_size)
处理完Mnist数据后,我们需要定义一个cnn网络来对数据集进行训练,我们这里搭建一个四个卷积层的CNN,具体结构参数见下表:
| 网络结构 | 输入(N,C,W,H) | 卷积核 (大小,输入,输出) | 激活函数 | 输出图像(N,C,W,H) |
|---|---|---|---|---|
| conv1 | [128,1,28,28] | [3,3,1,16] | ReLU | [128,16,14,14] |
| conv2 | [128,16,14,14] | [3,3,16,32] | ReLU | [128,32,7,7] |
| conv3 | [128,32,7,7] | [3,3,32,64] | ReLU | [128,64,4,4] |
| conv4 | [128,64,4,4] | [3,3,64,64] | ReLU | [128,64,2,2] |
# CNN结构定义:
# 定义网络结构
class CNNnet(torch.nn.Module):
def __init__(self):
super(CNNnet,self).__init__()# super用于调用父类(超类)
self.conv1=torch.nn.Sequential(
# 二维卷积
torch.nn.Conv2d(in_channels=1,# 输入图片的通道数
out_channels=16,# 卷积产生的通道数
kernel_size=3,# 卷积核尺寸
stride=2,# 步长
padding=1),# 补0数
torch.nn.BatchNorm2d(16),# 数据在进入ReLU前进行归一化处理,num_features=batch_size*num_features*height*width
# 输出期望输出的(N,C,W,H)中的C (数量,通道,高度,宽度)
torch.nn.ReLU( )
)
self.conv2=torch.nn.Sequential(
torch.nn.Conv2d(16,32,3,2,1),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU()
)
self.conv3=torch.nn.Sequential(
torch.nn.Conv2d(32,64,3,2,1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.conv4=torch.nn.Sequential(
torch.nn.Conv2d(64,64,2,2,0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
# 全连接层参数设置
self.mlp1=torch.nn.Linear(2*2*64,100)# 为了输出y=xA^T+b,进行线性变换(输入样本大小,输出样本大小)
self.mlp2=torch.nn.Linear(100,10)
def forward(self,x):# 前向传播
x=self.conv1(x)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.mlp1(x.view(x.size(0),-1))# 将多维度的tensor展平成一维
x=self.mlp2(x)
return x
model=CNNnet()
print(model)#输出模型写完网络模型结构后,我们需要对模型的优化器进行定义:
# 定义损失函数和优化器
loss_func=torch.nn.CrossEntropyLoss( )# 使用交叉熵损失函数
# 使用Adam函数优化器,输入模型的参数与学习率lr
opt=torch.optim.Adam(model.parameters( ),lr=0.001)通过优化器进行梯度下降的具体步骤如下:
loss=loss_func(out,batch_y) opt.zero_grad()loss.backward()net的parmeters上:opt.step() 此外再举pytorch环境下的优化器定义的几个例子:
# 使用Adam函数优化器,输入模型的参数与学习率lr
opt=torch.optim.Adam(model.parameters( ),lr=0.001)
# SGD 就是随机梯度下降
opt=torch.optim.SGD(model.parameters( ), lr=0.001)
# momentum 动量加速,在SGD函数里指定momentum的值即可
opt=torch.optim.SGD(model.parameters( ), lr=0.001, momentum=0.8)
# RMSprop 指定参数alpha
opt=torch.optim.RMSprop(model.parameters( ), lr=0.001, alpha=0.9)对同一网络模型使用不同优化器对minist数据集进行处理后的到的损失函数图像如图1~4所示(使用的损失函数为交叉熵函数):
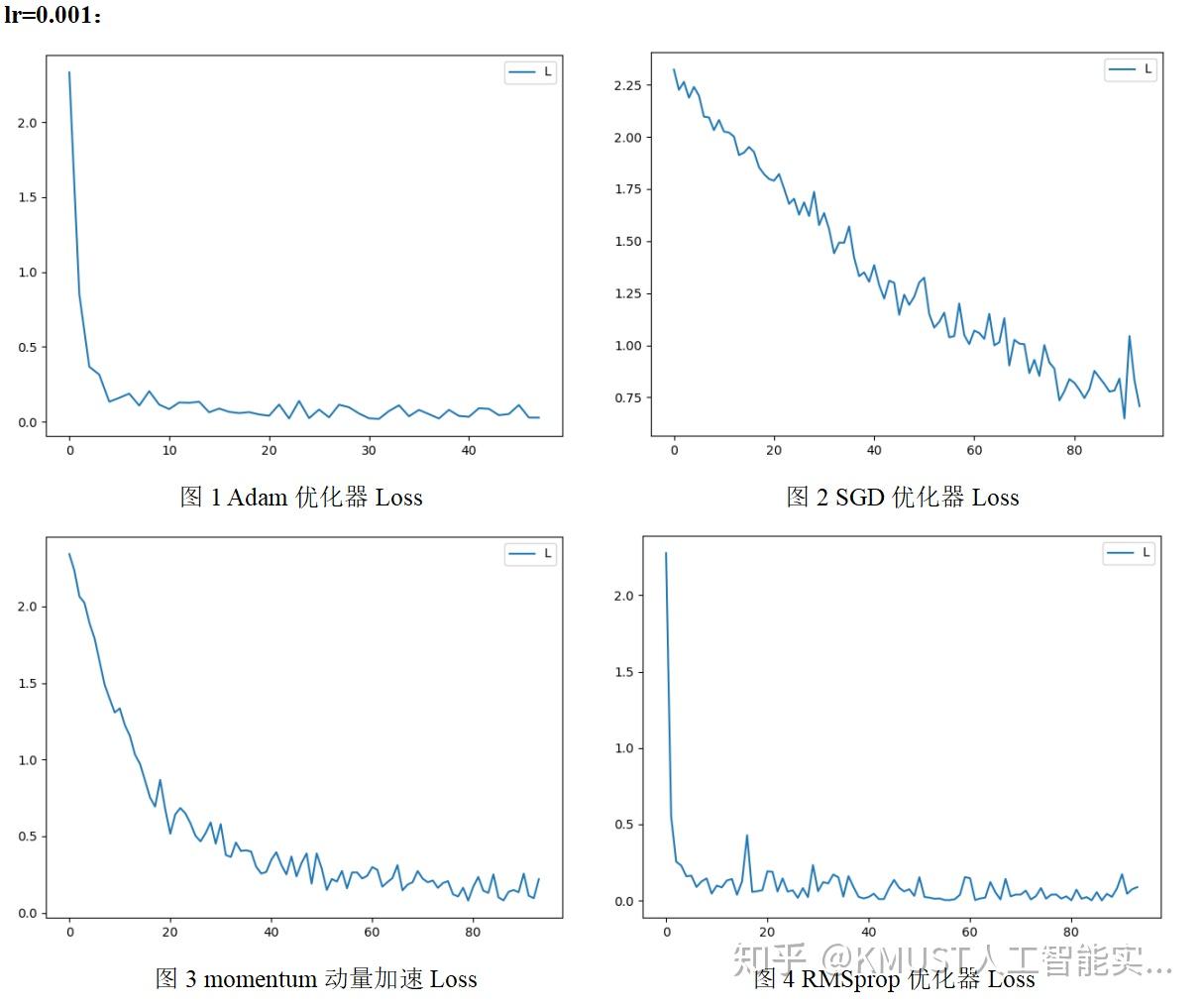
优化器总结:
1、SGD优化器:
优点:cost fuction若为凸函数,能够保证收敛到全局最优值;若为非凸函数,能够收敛到局部最优值
缺点:
①由于每轮迭代都需要在整个数据集上计算一次,所以批量梯度下降可能非常慢
②训练数较多时,需要较大内存批量梯度下降
③不允许在线更新模型,例如新增实例。
2、Momentum:
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向,但比较难学习一个较好的学习率。
3、RMSprop
RMSprop是Geoff Hinton提出的一种自适应学习率方法。Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题,依然依赖一个全局学习率。
4、Adam
结合了动量和RMSProp,利用了梯度的一阶矩估计和二阶矩估计动态调节每个参数的学习率,并且加上了偏置修正。
除了优化器的选择以外,我们还须对每种优化器的学习率进行设置,对Adam优化器进行不同学习率设置后如图5~9所示:
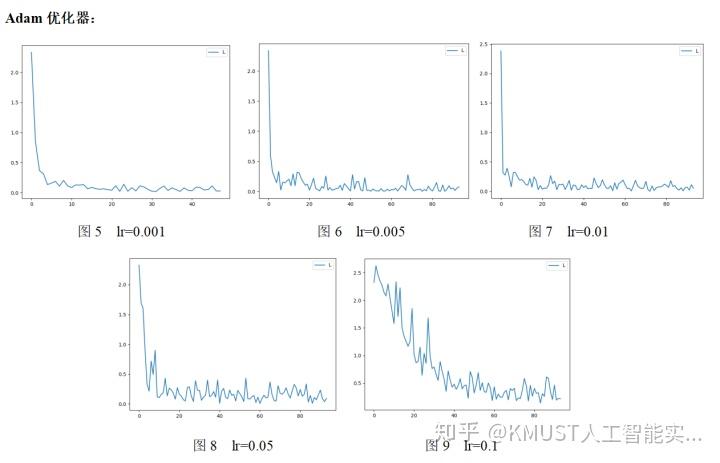
学习率总结:
学习率太小,更新速度慢;学习率过大,可能跨过最优解。因此,在刚开始训练,距离最优解较远时可以采用稍大的学习率,随着迭代次数增加,在逼近最优解的过程中,逐渐减小学习率。
以上我们便以处理Mnist数据集为了,对不同优化器与损失函数进行了直观的对比,全部代码见附录code,导入cv2库是为了对单张图像进行处理,只想对Mnist数据集进行训练的可以去掉main函数部分,不导入cv2库来运行程序。
Reference:
[1]https://www.matools.com/blog/190399301
[2]https://blog.csdn.net/u010089444/article/details/76725843
[3]https://blog.csdn.net/qq_34714751/article/details/85610966
code:
#导入所需要的包
import torch
import cv2
from torch.utils import data # 获取迭代数据
from torch.autograd import Variable # 获取变量
import torchvision
from torchvision.datasets import mnist # 获取数据集
import matplotlib.pyplot as plt
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据集的预处理
data_tf = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor( ),# 将原有数据转化成张量图像,值在(0,1)
torchvision.transforms.Normalize([0.5],[0.5])# 将数据归一化到(-1,1)
]
)
# 数据集获取路径设置
data_path = r'D:\\my_data\\MNIST100Collection\\Datasets'
# 数据集的获取
train_data = mnist.MNIST(data_path,train=True,transform=data_tf,download=False)
test_data = mnist.MNIST(data_path,train=True,transform=data_tf,download=False)
# 获取迭代数据
train_loader = data.DataLoader(train_data,batch_size=64,shuffle=True)# 训练数据,batch用于一次反向传播参数更新
test_loader = data.DataLoader(test_data,batch_size=100,shuffle=True)# 测试数据,shuffle是打乱数据的意思(多次取出batch_size)
# 定义网络结构
class CNNnet(torch.nn.Module):
def __init__(self):
super(CNNnet,self).__init__()# super用于调用父类(超类)
self.conv1 = torch.nn.Sequential(
# 二维卷积
torch.nn.Conv2d(in_channels=1,# 输入图片的通道数
out_channels=16,# 卷积产生的通道数
kernel_size=3,# 卷积核尺寸
stride=2,# 步长
padding=1),# 补0数
torch.nn.BatchNorm2d(16),# 数据在进入ReLU前进行归一化处理,num_features=batch_size*num_features*height*width
# 输出期望输出的(N,C,W,H)中的C (数量,通道,高度,宽度)
torch.nn.ReLU( )
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(16,32,3,2,1),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU()
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(32,64,3,2,1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.conv4 = torch.nn.Sequential(
torch.nn.Conv2d(64,64,2,2,0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
# 全连接层参数设置
self.mlp1 = torch.nn.Linear(2*2*64,100)# 为了输出y=xA^T+b,进行线性变换(输入样本大小,输出样本大小)
self.mlp2 = torch.nn.Linear(100,10)
def forward(self,x):# 前向传播
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.mlp1(x.view(x.size(0),-1))# 将多维度的tensor展平成一维
x = self.mlp2(x)
return x
model = CNNnet()
print(model)#输出模型
# 定义损失和优化器
loss_func = torch.nn.CrossEntropyLoss( )# 使用交叉熵损失函数
# 使用Adam函数优化器,输入模型的参数与学习率lr
opt = torch.optim.Adam(model.parameters( ),lr=0.001)
# SGD 就是随机梯度下降
#opt=torch.optim.SGD(model.parameters( ), lr=0.001)
# momentum 动量加速,在SGD函数里指定momentum的值即可
#opt=torch.optim.SGD(model.parameters( ), lr=0.001, momentum=0.8)
# RMSprop 指定参数alpha
#opt=torch.optim.RMSprop(model.parameters( ), lr=0.001, alpha=0.9)
# 训练网络
loss_count = []
for epoch in range(2):
for i,(x,y) in enumerate(train_loader):
batch_x = Variable(x) # torch,Size([128,1,28,28])将张量转为变量
batch_y = Variable(y) # torch.Size([128])
# 获取最后输出
out = model(batch_x) # torch.Size([128,10])
# 获取损失
loss = loss_func(out,batch_y)
# 使用优化器优化损失
opt.zero_grad() # 清空上一步残余更新参数值,把模型中参数的梯度设为0
loss.backward() # 误差方向传播计算参数更新值,计算与图中叶子结点有关的当前张量的梯度
opt.step() # 将参数更新值施加到net的parameters上,根据梯度更新网络参数
if i % 20 == 0:
loss_count.append(loss)
print('{}:\ '.format(i),loss.item())
torch.save(model.state_dict(),r'D:\\my_data\\MNIST100Collection\\log_CNN')
if i % 100 == 0:
for a,b in test_loader:
test_x = Variable(a)
test_y = Variable(b)
out = model(test_x)
# print('test_out:\ ',torch.max(out,1)[1])
# print('test_y:\ ',test_y)
accuarcy = torch.max(out,1)[1].numpy() == test_y.numpy()# 获得当前softmax层最大概率对应的索引值
print('accuary:\ ',accuarcy.mean())
break
plt.figure('PyTorch_CNN_Loss')
plt.plot(loss_count,label='Loss')
plt.legend('Loss')#给图片加图例
plt.show()
net = CNNnet().to(device)
if __name__ == "__main__":
# train()
img = cv2.imread('D:\\my_data\\MNIST100Collection/number5.jpg', cv2.IMREAD_GRAYSCALE) #读取图片
img = cv2.resize(img,(28, 28)) # 调整图片为28*28
cv2.namedWindow('input_image', cv2.WINDOW_AUTOSIZE)
cv2.resizeWindow("input_image", 640, 480);
cv2.imshow('input_image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = torch.from_numpy(img).float()
img = img.view(1, 1, 28, 28)
img = img.to(device)
outputs = net(img)
_, predicted = torch.max(outputs.data, 1)
print(predicted.to('cpu').numpy().squeeze())






