
北京某某塑料板材有限公司
诚信 / 务实 / 完善 / 快速 / 放心 - 国际品牌
咨询热线: 020-88888888
当前位置: 主页 > 资讯中心 > 公司新闻 » pytorch07:损失函数与优化器


pytorch01:概念、张量操作、线性回归与逻辑回归
pytorch02:数据读取DataLoader与Dataset、数据预处理transform
pytorch03:transforms常见数据增强操作
pytorch04:网络模型创建
pytorch05:卷积、池化、激活
pytorch06:权重初始化
从下面的一元函数可以看出,直线拟合的点和真实值之间存在误差,这个误差就是损失函数。
损失函数:计算一个样本的差异。
代价函数:样本数据集所有损失的平均值。
目标函数:代价函数+Regularization(对模型的约束)
Regularization:为了防止模型过拟合,需要添加该项对模型进行约束
一般用代价函数来表示模型的损失函数


功能: nn.LogSoftmax() 与 nn.NLLLoss() 结合,进行交叉熵计算
LogSoftmax:将数据归一化到一个概率取值的范围 0~1
NLLLoss():使用概率值计算交叉熵
主要参数:
? weight:各类别的loss设置权值
? ignore_index:忽略某个类别
? reduction :计算模式,可为none/sum /mean
none- 逐个元素计算
sum- 所有元素求和,返回标量
mean- 加权平均,返回标量
交叉熵损失函数继承的父类损失:
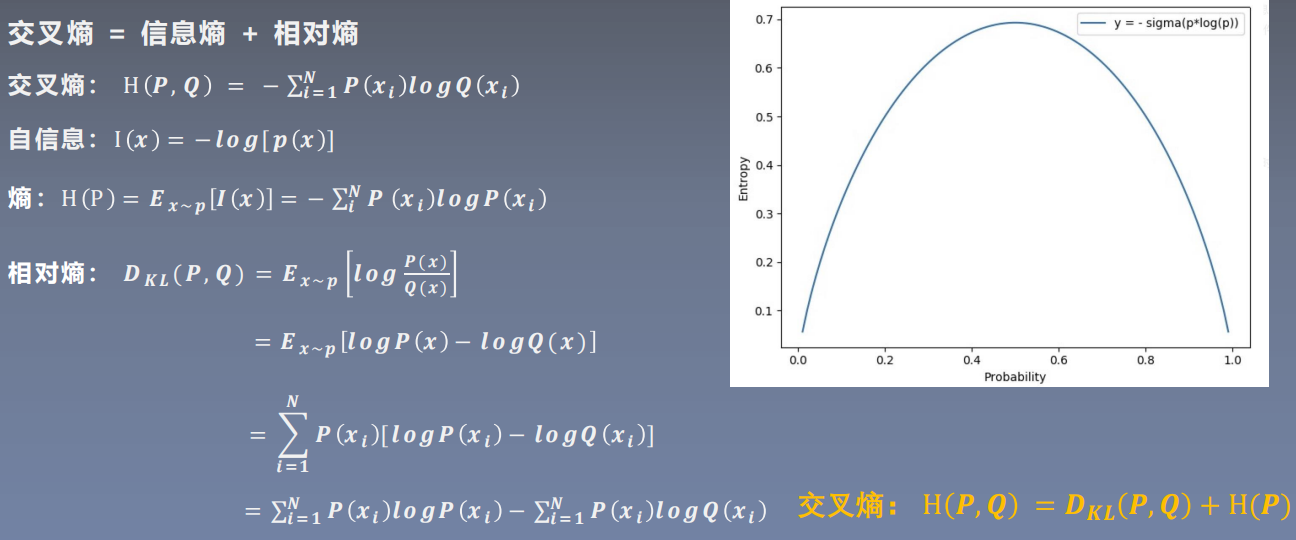
熵:表示自信息的期望
自信息:用于衡量单个事件的不确定性
右图表示信息熵:当概率为0.5左右的时候,信息熵最大。
P表示原始数据的概率分布,Q表示模型输出的概率分布。
从公式可以看出优化交叉熵也就是优化相对熵,因为H§是一个常数。
输出结果:
使用交叉熵损失计算和手动设计公式计算得到的结果相同。

代码实现:
设计第一个样本的权重为1,后两个样本的权重为2
输出结果:
注意:在计算平均损失的时候,不再是总损失/3个样本,而是做了一个加权的求平均,第一个样本的权值是1,那就算1个样本,第2,3个样本的权值为2,所以算4个样本,损失的平均值为1.821/5=0.3642。

功能:实现负对数似然函数中的负号功能
主要参数:
? weight:各类别的loss设置权值
? ignore_index:忽略某个类别
? reduction:计算模式,可为none/sum/mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
输出结果:
该函数只是对输出结果进行添加符号处理

功能:二分类交叉熵,对每一个神经元一一计算loss
注意事项:输入值取值在[0,1]
主要参数:
? weight:各类别的loss设置权值
? ignore_index:忽略某个类别
? reduction :计算模式,可为none/sum/mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
注意:使用该函数,如果输入的值不是0~1之间的数据,需要添加sigmoid函数。
输出结果:
对每一个神经元计算loss

功能:结合Sigmoid与二分类交叉熵
注意事项:使用该函数,网络最后不加sigmoid函数
主要参数:
? pos _weight :正样本的权值
? weight:各类别的loss设置权值
? ignore_index:忽略某个类别
? reduction :计算模式,可为none/sum/mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
输出结果:

如果再使用sigmoid函数会导致损失函数发生变化,如下:

机器学习模型训练有以下几个步骤,优化器是在哪一步开始使用呢?
将数据输入到模型当中会得到一个output值,将output值和target目标值放入到损失函数计算损失,损失使用反向传播的方法求出训练过程中每一个参数的梯度,优化器拿到梯度,使用优化策略,减少损失。

pytorch的优化器:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签
导数:函数在指定坐标轴上的变化率
方向导数:指定方向上的变化率
梯度:一个向量,方向为方向导数取得最大值的方向
梯度下降:朝着梯度的负方向取变化,也就是变化最快的
 基本属性
基本属性
? defaults:优化器超参数。
? state:参数的缓存,如momentum的缓存(前几次更新的梯度)。
? params_groups:管理的参数组,list类型中存储的字典类型。
? _step_count:记录更新次数,学习率调整中使用。
作用:清空所管理参数的梯度。
为什么使用该方法,这是因为pytorch特性:张量梯度不自动清零;

代码实现:
输出结果:
通过输出可以看出优化器当中存储的是参数变量的地址,不需要额外使用内存保存梯度;

作用:执行一步更新

代码实现:
结果输出:
当我们设置梯度为1,学习率为1的时候,输出结果=输入数据-梯度;

当我们设置梯度为1,学习率为0.1的时候,输出结果=输入数据-梯度;

作用:添加参数组
对于不同的组有不同的超参数设置,例如一个深度学习模型,我们对特征提取模块的学习率设置小一些,让它更新慢一点,在全连接层可以设置学习率大一些。

代码实现:
输出结果:
将一个新的参数组

作用:获取优化器当前状态信息字典
当我们训练需要中断的时候可以使用该方法,将当前训练的参数保存下来。

代码实现:
输出结果:
将10次step的结果保存在optimizer_state_dict.pkl当中,同时会在当前文件夹生成一个新的文件。


作用:加载状态信息字典
用于读取上一次训练所保存的参数;

代码实现:
输出结果:

对y=4
x
2
x^2
x2使用梯度下降的方法更新参数,使其到达最低点,发现在计算到第三次的时候,y的值变的很大,并没有减少参数,反而变的更大。

代码实现:
输出结果:

当学习率设置为1,通过输出结果可以发现,随着迭代次数的增加,数值更新的步伐越大,损失值越大。那么如何解决这个问题呢。
通过设置学习率可以控制每次梯度下降的更新步伐大小。

代码展示:

输出结果:

当学习率设置过小为0.01时,10次迭代结果如下,会发现需要迭代多长才能梯度下降到最优值:

经过上次两次会发现学习率过大或者过小都不合适,那么如何找到一个最优的学习率可以提高梯度下降的速率?
使用多尺度学习率做测试,选取学习率区间0.01~0.2,在该区间划分10个等间距的学习率进行实验。
代码实现:
实验结果:

通过实验结果发现,当学习率在0.136的时候,此时会更快降低损失,y的值更快到达最小值。
结合当前梯度与上一次更新信息,用于当前更新
优化器中的momentum是指动量(Momentum),它是一种在优化算法中常用的技术,用于加速参数的更新。动量是在每次更新参数时,将之前的一次更新作为一部分权重加入到当前的更新中,从而使得参数的更新更加平滑,减少了震荡。
在优化过程中,优化器会根据损失函数和模型参数计算梯度。但是,由于模型参数可能存在多个局部最小值,优化器可能会在损失函数曲面上跳跃式地移动,导致参数更新剧烈,甚至出现震荡。动量技术通过引入历史更新信息,使得优化器能够更好地平滑地移动到最优解,从而减少了震荡和过拟合的风险。
在PyTorch等深度学习框架中,优化器通常会内置动量参数,用户只需要在创建优化器时指定学习率和优化器类型,框架会自动计算动量值并应用于优化过程。
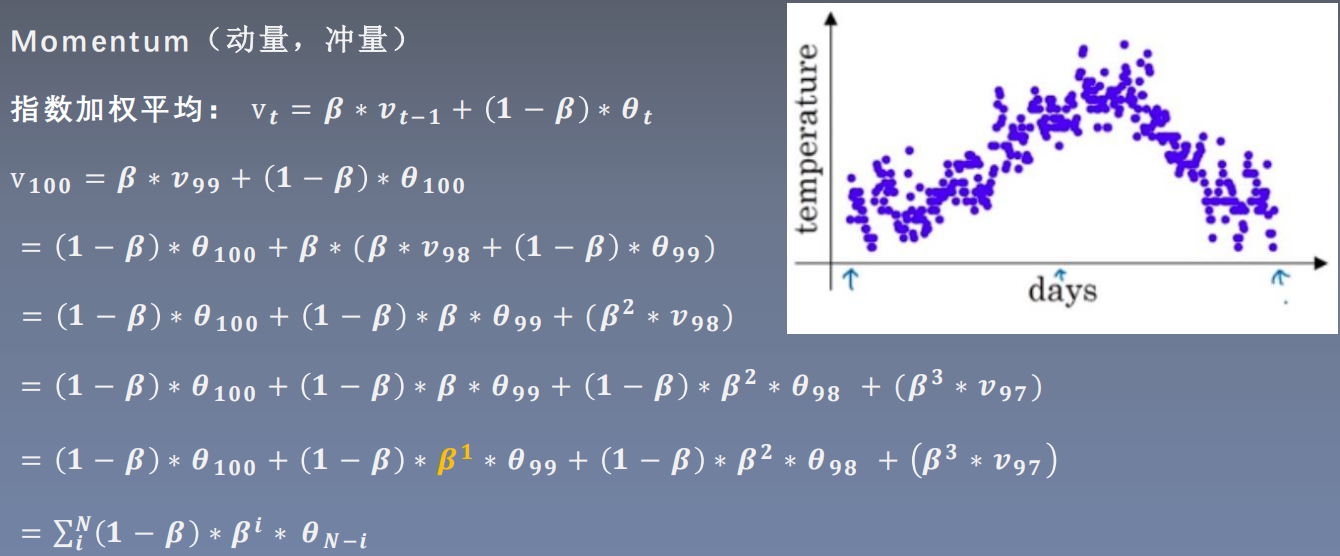
首先了解一下指数加权平均,数学思想:要求取当前时刻的平均值,距离当前时刻越近的参数值,参考价值越大,所占的权重越大,这个权重随着时间间隔的增大呈指数下降。
代码实现:
实现结果:

通过代码实现可以看出,距离当前时刻越远,它对当前时刻的平均值越小。
当设置多个beta值的实验结果如下:

通过实验可以看出,beta 可以理解为记忆周期,当beta值越小,记忆周期越短,beta=0.8时,当到达20天的时候就不再关注远期的一个记忆值;beta值越大,记忆周期也就越长。
添加momentum更新之后的公式不仅仅只考虑当前的梯度,还要考虑上一次更新梯度乘以m的值,以及上上次梯度*
m
2
m^2
m2…,距离当前时刻越远的值,对当前的影响越小,因为m是个小于1的数。

实验一:设置momentum为0,学习率分别为0.01和0.03时函数收敛速率。
代码:
实验结果:

实验结果分析:因为黄色部分学习率更高,所以收敛的速率比较快。
实验二:设置学习率0.01时,momentum为0.9
实验结果如下:

实验结果分析:虽然0.01的学习率比较低,但是添加momentum之后收敛速率增加;为什么会出现波浪?因为在收敛到最小值的时候仍然保留着之前的权重,所以没法快速收敛到一个平稳值。

? params:管理的参数组
? lr:初始学习率
? momentum:动量系数,贝塔
? weight_decay:L2正则化系数
? nesterov:是否采用NAG













